很久之前写的东西,有不少谬误。维特比算法应该特指定义在栅格网络上的动态规划算法,其在分词中的应用请参考维特比算法。
在维特比算法通俗理解中,记录了我对维特比算法的粗浅理解,这里结合Ansj中文分词的源码,记录一下维特比算法在分词中的应用。
原子分词
Ansj分词的第一步是原子切分,所谓原子切分就是将一个句子拆成所有可能的单词,比如“商品和服务”就会被拆成:
始##始
商品/n 商/n
品/v
和服/n 和/c
服务/vn 服/v
务/dg
末##末
每一行实际上有多列,分别是一个term和它的前缀term。如果没有多列的话,也即是前缀term是null。每一行实际上是通过Tire树最长匹配找出来的最长词以及路径上路过的前缀相同词。
构图
所谓构图,就是使用构建一个邻接表来储存图。利用每个term的offset来判断它在什么位置,然后将term加入到邻接表数组terms[offset]处,如果terms[offset]已经被占用了,那么就在写入之前,将term的next指针设为已存在的节点。
其实在Ansj分词的实现中,原子切分和构图是同时进行的,每切出一个词就将其加入到图中。为了好理解,我将其分为逻辑上的这两步。
经过构图,我们得到了如下有向图:
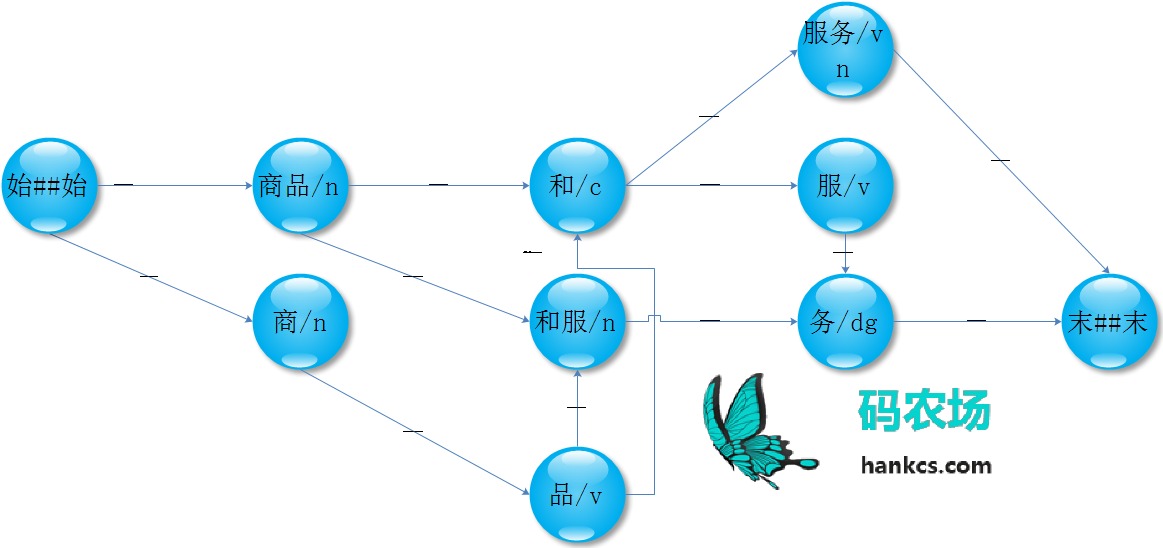
两个词之间的距离
我们为了计算两个节点term之间的距离,需要一份词典,这份词典在Ansj中对应于bigramdict.dic这个文件。
这个文件的结构是
from@to frequency
继续@挖潜1
继续@完成1
继续@完善2
继续@往1
继续@为4
代表着词from下一个词是to的频次,这个频次据说是通过很多语料的统计得出的结果。
其实这里还有一个隐藏数据,那就是每一行的index,这个index是通过查询from和to在双数组Tire树中的index而来的,然后储存在动态数组result[index of from][some index] = new BigramEntry(index of to, frequency) 。
其中some index是动态数组里的index,BigramEntry是一个包装了id-frequency的数据结构,这些都是细微末节,不用太在意。
那么两个节点from和to之间的距离就是
dim allFrequency as from 转移到其他词的频次之和
dim nTwoWordsFreq as TwoWordFreq(from, to);
dim distance as distance(from, to)
distance = -log(allFrequency + nTwoWordsFreq / allFrequency )
当然具体实现比这份“伪码”复杂得多,涉及到了平滑因子和除零错误等,不过为了突出重点,就这么理解也无妨。
可见两个term之间转换的频次越多,它们的距离就越小。只要知道这一点就足够理解接下来的算法了。毕竟这个平滑因子的选取尚无定论,(这个公式到有点像熵的计算公式,错觉吗?),忽略它们吧。
最短路径
回忆一下维特比算法:到B的最短路径只取决于节点A的最短路径以及A到B的最短路径。
于是ansj分词中给每个节点分配了一个distance,代表从根节点到当前节点的累计最短路径的长度(代码中名称是score,但是我觉得还是distance好理解),然后一个dfs遍历整个图打分,每次打分只要加上from的距离和to的距离就行了。其难度小于一道基础的dfs ACM题目。
我给“商品和服务”的词图画了一张图帮助理解:
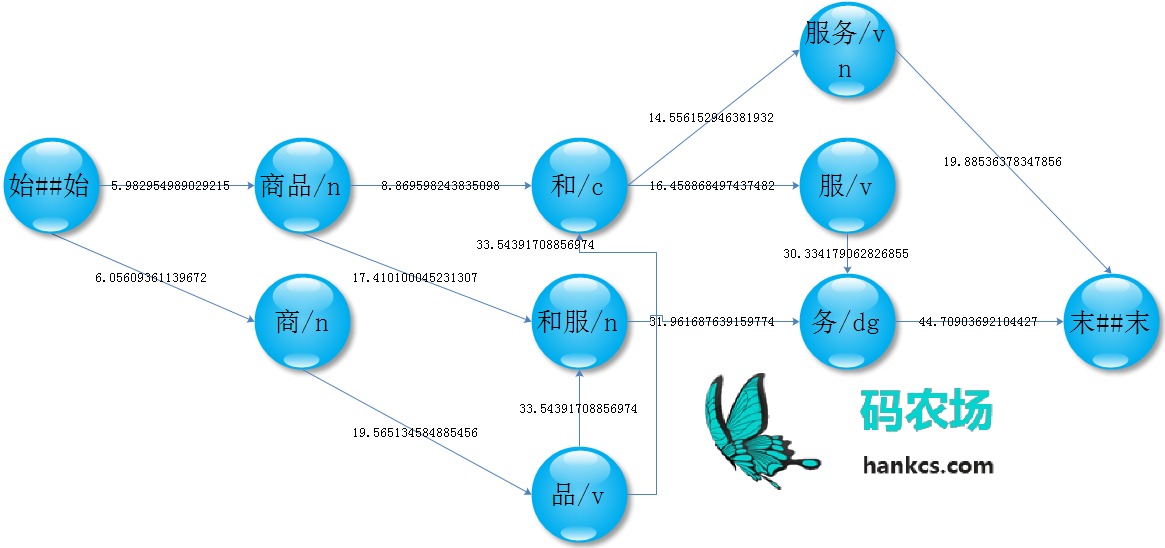
我们不妨从末尾节点开始观察,一共有两条路径到末尾,其中“服务”那一条更短,那么“服务”就是最佳分词中的倒数第一个词,如此类推,得出最佳分词路径为:
[商品/n, 和/c, 服务/vn]
事实上,在“商品”这个分岔点上,去“和服”“和”这两条路的远近就是一个典型,从“商品”转移到“商品和服”的难度远远高于“商品和”的难度。
这篇博文中的最短路径和Viterbi算法似乎关系不大吧, 况且Viterbi算法只对Latice Graph有最优解.
你好,参数是凭经验给的,前者是大约使两个词的cost大于一整个时的量,后者是词频之和。维特比没有看论文,是看wiki百科写的。
博主,你好,请问HanLp的Predefine中dSmoothingPara MAX_FREQUENCY dTemp 分别是怎么来的呢,用维特比求路径的时候公式有没有论文可以参考一下,公式的原理不太明白,谢谢
你可以参考下这个:https://github.com/hankcs/HanLP/issues/120
最好还是去github项目主页上找答案
博主,请问如果词典中没有商品to服装没有呢?
靠平滑
“奥巴马带了6本书籍”,这句话总是分成“奥 巴马ns 带 了 6 本书 籍”,明显有2个错误。我发现核心词典中“奥巴马nrf1200”,"巴马ns24",2元词典中没有“奥巴马to带”和“巴马to带”,但是单步跟踪发现“巴马to带”竟有80之多!跪求博主试一下下O(∩_∩)O~~
请通过HanLP.Config.enableDebug();观察。
ns被转义为未##地,未##地to带有可能有很多。
另外,你似乎用的是旧版本。新版本已经能出正确结果了:
奥巴马/nr, 带/v, 了/ule