谈起自动摘要算法,常见的并且最易实现的当属TF-IDF,但是感觉TF-IDF效果一般,不如TextRank好。
TextRank是在Google的PageRank算法启发下,针对文本里的句子设计的权重算法,目标是自动摘要。它利用投票的原理,让每一个单词给它的邻居(术语称窗口)投赞成票,票的权重取决于自己的票数。这是一个“先有鸡还是先有蛋”的悖论,PageRank采用矩阵迭代收敛的方式解决了这个悖论。TextRank也不例外:
PageRank的计算公式:
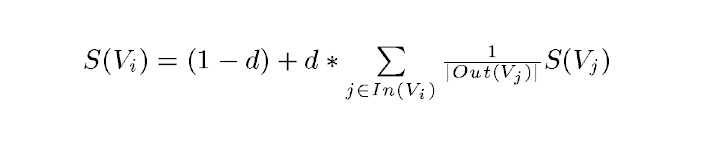
正规的TextRank公式
正规的TextRank公式在PageRank的公式的基础上,引入了边的权值的概念,代表两个句子的相似度。
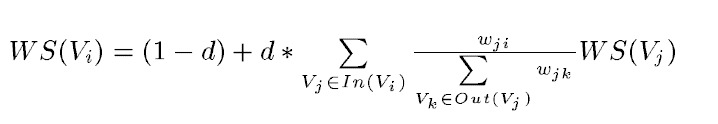
但是很明显我只想计算关键字,如果把一个单词视为一个句子的话,那么所有句子(单词)构成的边的权重都是0(没有交集,没有相似性),所以分子分母的权值w约掉了,算法退化为PageRank。所以说,这里称关键字提取算法为PageRank也不为过。
另外,如果你想提取关键句(自动摘要)的话,请参考姊妹篇《TextRank算法自动摘要的Java实现》。
TextRank的Java实现
先看看测试数据:
程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。
我取出了百度百科关于“程序员”的定义作为测试用例,很明显,这段定义的关键字应当是“程序员”并且“程序员”的得分应当最高。
首先对这句话分词,这里可以借助各种分词项目,比如HanLP分词,得出分词结果:
[程序员/n, (, 英文/nz, programmer/en, ), 是/v, 从事/v, 程序/n, 开发/v, 、/w, 维护/v, 的/uj, 专业/n, 人员/n, 。/w, 一般/a, 将/d, 程序员/n, 分为/v, 程序/n, 设计/vn, 人员/n, 和/c, 程序/n, 编码/n, 人员/n, ,/w, 但/c, 两者/r, 的/uj, 界限/n, 并/c, 不/d, 非常/d, 清楚/a, ,/w, 特别/d, 是/v, 在/p, 中国/ns, 。/w, 软件/n, 从业/b, 人员/n, 分为/v, 初级/b, 程序员/n, 、/w, 高级/a, 程序员/n, 、/w, 系统/n, 分析员/n, 和/c, 项目/n, 经理/n, 四/m, 大/a, 类/q, 。/w]
然后去掉里面的停用词,这里我去掉了标点符号、常用词、以及“名词、动词、形容词、副词之外的词”。得出实际有用的词语:
[程序员, 英文, 程序, 开发, 维护, 专业, 人员, 程序员, 分为, 程序, 设计, 人员, 程序, 编码, 人员, 界限, 特别, 中国, 软件, 人员, 分为, 程序员, 高级, 程序员, 系统, 分析员, 项目, 经理]
之后建立两个大小为5的窗口,每个单词将票投给它身前身后距离5以内的单词:
{开发=[专业, 程序员, 维护, 英文, 程序, 人员],
软件=[程序员, 分为, 界限, 高级, 中国, 特别, 人员],
程序员=[开发, 软件, 分析员, 维护, 系统, 项目, 经理, 分为, 英文, 程序, 专业, 设计, 高级, 人员, 中国],
分析员=[程序员, 系统, 项目, 经理, 高级],
维护=[专业, 开发, 程序员, 分为, 英文, 程序, 人员],
系统=[程序员, 分析员, 项目, 经理, 分为, 高级],
项目=[程序员, 分析员, 系统, 经理, 高级],
经理=[程序员, 分析员, 系统, 项目],
分为=[专业, 软件, 设计, 程序员, 维护, 系统, 高级, 程序, 中国, 特别, 人员],
英文=[专业, 开发, 程序员, 维护, 程序],
程序=[专业, 开发, 设计, 程序员, 编码, 维护, 界限, 分为, 英文, 特别, 人员],
特别=[软件, 编码, 分为, 界限, 程序, 中国, 人员],
专业=[开发, 程序员, 维护, 分为, 英文, 程序, 人员],
设计=[程序员, 编码, 分为, 程序, 人员],
编码=[设计, 界限, 程序, 中国, 特别, 人员],
界限=[软件, 编码, 程序, 中国, 特别, 人员],
高级=[程序员, 软件, 分析员, 系统, 项目, 分为, 人员],
中国=[程序员, 软件, 编码, 分为, 界限, 特别, 人员],
人员=[开发, 程序员, 软件, 维护, 分为, 程序, 特别, 专业, 设计, 编码, 界限, 高级, 中国]}
然后开始迭代投票:
for (int i = 0; i < max_iter; ++i)
{
Map<String, Float> m = new HashMap<String, Float>();
float max_diff = 0;
for (Map.Entry<String, Set<String>> entry : words.entrySet())
{
String key = entry.getKey();
Set<String> value = entry.getValue();
m.put(key, 1 - d);
for (String other : value)
{
int size = words.get(other).size();
if (key.equals(other) || size == 0) continue;
m.put(key, m.get(key) + d / size * (score.get(other) == null ? 0 : score.get(other)));
}
max_diff = Math.max(max_diff, Math.abs(m.get(key) - (score.get(key) == null ? 0 : score.get(key))));
}
score = m;
if (max_diff <= min_diff) break;
}
排序后的投票结果:
[程序员=1.9249977,
人员=1.6290349,
分为=1.4027836,
程序=1.4025855,
高级=0.9747374,
软件=0.93525416,
中国=0.93414587,
特别=0.93352026,
维护=0.9321688,
专业=0.9321688,
系统=0.885048,
编码=0.82671607,
界限=0.82206935,
开发=0.82074183,
分析员=0.77101076,
项目=0.77101076,
英文=0.7098714,
设计=0.6992446,
经理=0.64640945]
程序员果然荣登榜首,并且分数也有区分度,嗯,勉勉强强。
开源项目地址
本文代码已集成到HanLP中开源:http://www.hankcs.com/nlp/hanlp.html
目前能够提供分词、词性标注、命名实体识别、关键字提取、短语提取、自动摘要、自动推荐,依存关系、句法树等功能。
初值采用sigmoid函数来赋值,实测上面的示例计算从37轮迭代降低为9轮。我是用scala测试的,Java类似这样
Map score = new HashMap();
for (Map.Entry<String, Set> entry : words.entrySet()){
score.put(entry.getKey(),sigmoid(entry.getValue().size());
}
上面的初值应描述为key对应的set size除以key total count,这样更准确
在初始化score时,Map score = new HashMap(); 可以给score赋带权重的初值,比如是每个key的set.size/key number,这样能加快收敛,实测能节省10%以上的迭代次数
“之后建立两个大小为5的窗口,每个单词将票投给它身前身后距离5以内的单词:”,建立窗口获得(key,set[String])的列表之后,关键词不用再计算textrank了,直接比较set.size就可以得到结果,其结果与textrank一样,因为边的权重一样,请作者核实,是否节省了算力
alert(“1”)
123
我看不懂java,但是textrank不是应该和pagerank一样,都是分数加起来和为1么?
这种最简单构建的模型,直观上来讲性能基本不会比单独使用词频进行排序强到哪去
一月 08, 2016 3:34:17 下午 org.ansj.util.MyStaticValue getCRFSplitWord
信息: begin init crf model!
一月 08, 2016 3:34:24 下午 org.ansj.util.MyStaticValue getCRFSplitWord
信息: load crf crf use time:6983
我也是
博主你好,最近看了原论文里面有这样一句:After the graph is constructed (undirected
unweighted graph), the score associated with each
vertex is set to an initial value of 1, and the ranking
algorithm described in section 2 is run on the graph
for several iterations until it converges – usually for
20-30 iterations, at a threshold of 0.0001
意思是每个点的初始值是赋为1吧,但是看到你的代码里面好像是赋值为0,但后来往回看又看到
Notice that the final values
obtained after TextRank runs to completion are not
affected by the choice of the initial value, only the
number of iterations to convergence may be differ-
ent.
所以是不是初始值真的是对最后结果没有影响的;
另外,除了他说的迭代次数可能会影响之外,那个阈值是否也会影响,我试了一下不同阈值好像是有影响的,谢谢
对,跟初值无关,跟阀值有关,阀值是为了效率起见不迭代那么多次
请问那个迭代公式怎么来的 有引用吗?
我在http://www.cnblogs.com/FengYan/archive/2011/11/12/2246461.html和http://blog.csdn.net/hguisu/article/details/7996185中看到
迭代公式是求解X=AX的特征解:跟你那个迭代不一样啊
幂法计算过程如下:
X 设任意一个初始向量, 即设置初始每个网页的 PageRank值均。一般为1.
R = AX;
while (1 )(
if ( l X – R I < ) { //如果最后两次的结果近似或者相同,返回R
return R;
} else {
X =R;
R = AX;
}
}
文中第一个有下划线的TextRank就是论文链接,我只看论文。
博主,我自己添加了ansj分词里面的两个词典以及library.properties后,依然有一个警告,如下
二月 01, 2015 11:48:56 下午 org.ansj.util.MyStaticValue <clinit>
警告: not find library.properties in classpath use it by default !
二月 01, 2015 11:48:57 下午 org.ansj.library.InitDictionary init
信息: init core library ok use time :1038
二月 01, 2015 11:48:58 下午 org.ansj.library.UserDefineLibrary loadFile
信息: init user userLibrary ok path is : E:eclipseworkspaceTextRanklibrarydefault.dic
二月 01, 2015 11:48:58 下午 org.ansj.library.UserDefineLibrary initAmbiguityLibrary
信息: init ambiguityLibrary ok!
二月 01, 2015 11:49:00 下午 org.ansj.library.NgramLibrary <clinit>
信息: init ngram ok use time :2035
[温总理/nz, 离开/v, 了/ul, 舟曲/nz, 县城/n]
目测是library.properties路径放不对,我是直接放在项目根目录下的,请问应该放在哪里,十分感谢!虽然是警告,但强迫症受不了啊![[失望]](http://img.t.sinajs.cn/t35/style/images/common/face/ext/normal/0c/sw_org.gif "[失望]")
刚更新了下,试试最新的,这个问题严格上讲不关我事
文章中的代码和开源中的代码执行结果不一致啊
楼主你好,该项目是否提供自动摘要和情感分析这个功能??
这个项目只是一份简明的TextRankKeyword实现,不含其它。事实上,我正在开发一个汉语处理包,提供分词、词性标注、命名实体识别、关键字提取、短语提取、自动摘要、自动推荐等功能,未来可能开源,敬请期待~
最近在做个舆情项目,要做实体抽取,情感分析,关键词抽取等功能…….楼主继续努力,期待楼主的新项目
楼主在上文中不是提及“另外,如果你想提取关键句(自动摘要)的话,请参考姊妹篇《TextRank算法自动摘要的Java实现》。”吗,那个也是楼主发布的吗?是否可以提供TextRank算法自动摘要的Java实现的源代码供晚辈学习与研究?
在约掉Wij的情况下,连通数越多的节点越重要,这个就等同于TF了
楼主您好 我最近正在研究TextRank算法的实现问题但是无奈网上资料实在太少太过零碎 又是个技术菜鸟 对于java的使用很不扎实 看了您这篇日志 可不可以把你的完整代码给小弟参考一下?目前对于算法的实现仍旧处于一知半解的状态 感激不尽
没问题,我开了个项目https://github.com/hankcs/TextRank
跪谢 感激不尽!
楼主您好我在eclipse运行TextRankKeyword文件之后出现以下问题不知怎么回事?是我配置出错?已经把两个lib中的jar都build path建立了referenced library啊 求指教 :javaworkspaceTextRanklibrarydefault.dic because : not find that file or can not to read !
:javaworkspaceTextRanklibrarydefault.dic because : not find that file or can not to read ! :javaworkspaceTextRanklibraryambiguity.dic because : not find that file or can not to read !
:javaworkspaceTextRanklibraryambiguity.dic because : not find that file or can not to read !
五月 13, 2014 9:31:15 下午 org.ansj.util.MyStaticValue <clinit>
警告: not find library.properties in classpath use it by default !
五月 13, 2014 9:31:16 下午 org.ansj.library.InitDictionary init
信息: init core library ok use time :677
五月 13, 2014 9:31:16 下午 org.ansj.library.UserDefineLibrary loadLibrary
警告: init userLibrary waring
五月 13, 2014 9:31:16 下午 org.ansj.library.UserDefineLibrary initAmbiguityLibrary
警告: init ambiguity waring
五月 13, 2014 9:31:17 下午 org.ansj.library.NgramLibrary <clinit>
信息: init ngram ok use time :875
程序员#人员#是#程序#分为#系统#从事#非常#软件#清楚#
完全不影响的,jar是分词库,这几个警告是分词库发出的,原因是没有找到配置文件,它会自动用默认的
可是你的那个github里是不是没有配置文件的呢? 这里有三个警告 第一个我不知道什么问题 第二个和第三个警告中的default和ambiguity dic文件是不是要自己下载的呢 下载之后如何放入呢 楼主能否再详细告诉我一下你是如何配置这些分词器扩展包的呢 我一直云里雾里呀 多谢
我的项目里的确没有,分词不是TextRank关注的重点。非要说清楚的话,default.dic是用户词典,ambiguity.dic是歧义词典,详细的使用请上git搜索ansj就可以看到这个项目。