事实上,ansj实现的双数组没有通用性,你也无法往里面加入自己的词语,或者删除任何词语。我实现了一个通用的双数组trie树,提供更灵活的接口,更高的速度:http://www.hankcs.com/nlp/hanlp.html。
arrays.dic是一个双数组Trie树格式的词典,用文本的形式储存了索引,字串,base,check,status与词性。
一个直观的图示:
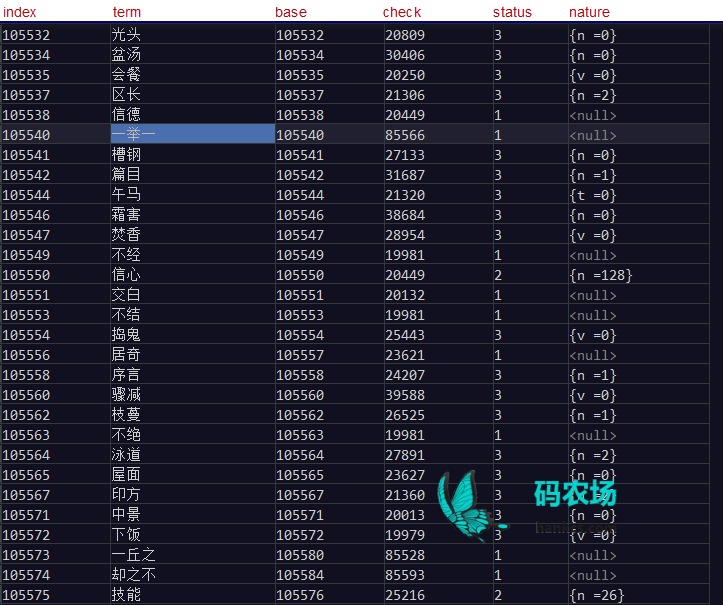
index就是base数组中的下标。
term是词的当前状态,不一定代表一个词,如“一举一”是“一举一动”的前缀。
base是base数组的值。代表字串的当前状态,其实就是字串一路按base[tx] = base[t] + x查过来的值。比如base[一举一动] = base[一举一] + code(动)。特别地,如果字串长度为1的话(字符),那么base值就是字符的双字节码。
check是check数组的值。check是用来验证这个词是从哪个状态转换过来的。比如![]() 是由
是由![]() 转换过来的。base[105540] + 21160 = 126700.
转换过来的。base[105540] + 21160 = 126700.
status是term的成词状态:1:继续 2:是个词语但是还可以继续 3:确定。参考。
nature是这个词以这些词性出现的频次。
博主,我想问一下,如果用双数组trie实现关键词匹配过滤,应该是很高效的吧?
多模式匹配应该用双数组AC自动机: http://www.hankcs.com/program/algorithm/aho-corasick-double-array-trie.html 或者简易AC自动机 :http://www.hankcs.com/program/algorithm/implementation-and-analysis-of-aho-corasick-algorithm-in-java.html
哦哦 好的 谢谢你 我看看 因为上次看资料说双数组trie可以满足10w关键词匹配,,,醉了