目录
Bigram语言模型中,分析的是连续两个词的组合概率。问题来了,“1人”和“2人”该怎么操作呢?这两个句子会被当成两种组合“1@人”和“2@人”,如果分别统计共现频次,会导致一个严重的问题,那就是对数词限定太死了,只在1人和2人的情况下能够统计到正确的频次,其他数词完全找不到共现词串,最后只能靠平滑处理来凑合一个频次。现实生活中“1000人”“一千人”这样的词组使用得还是相当频繁的,这会对分词器造成严重的影响。
测试用例
测试用例很简单,就拿“1人”举个例子。
民间分词器的缺陷
在一些民间分词器中,我并没有看到类似的处理,如ansj,在计算“1”到“人”的共现频次的时候,ansj只是机械地将两个词送到词典里去找,得出共现频次为0的答案。(当然,ansj中后续会有一个词性转换频率可以弥补这个错误,这是后话了)
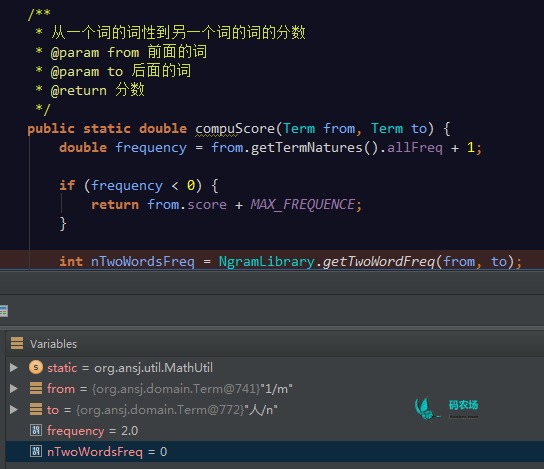
类似的情况还会发送在地名、人名、时间等词语上,需要动脑筋解决它。
ICTCLAS的“预编译”过程
ICTCLAS中有一个预处理过程,就是为数词等生成一个等效词串,比如“1000”->“未##数”,然后统计共现频次以及计算转换概率,在找到最佳路径之后将其还原为原来的词。比如这里的1就被“编译为”未##数,查词典的时候需要查询的是“未##数@人”:
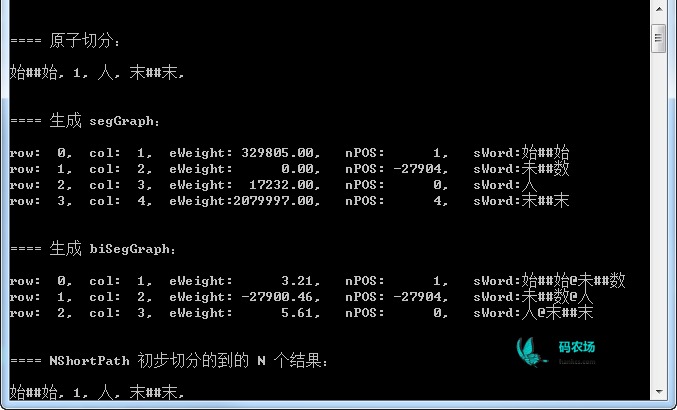
这样查出来的频次就不是0了,提高了分词的精确度。
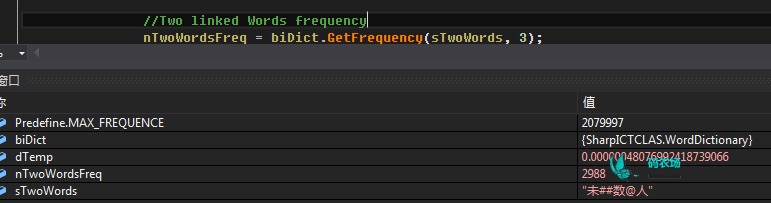
字典中的“预编译字串”
事实上字典中有相当数量的预编译字串,就连ansj抄过来的字典中也有不少:
[未##地, 始##始, 未##它, 未##团, 未##数, 未##专, 未##时, 未##串, 末##末, 未##人]
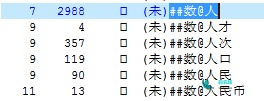
ICTCLAS中也有不少:
HanLP自然语言处理工具包
本文代码已集成到HanLP中开源,下载地址:https://github.com/hankcs/HanLP
支持中文分词(N-最短路分词、CRF分词、索引分词、用户自定义词典、词性标注),命名实体识别(中国人名、音译人名、日本人名、地名、实体机构名识别),关键词提取,自动摘要,短语提取,拼音转换,简繁转换,文本推荐,依存句法分析(基于神经网络的高性能依存句法分析器、MaxEnt依存句法分析、CRF依存句法分析)。提供Lucene插件,兼容Lucene4.x。