本文介绍一种简洁优雅的多标准中文分词方案,可联合多个不同标准的语料库训练单个模型,同时输出多标准的分词结果。通过不同语料库之间的迁移学习提升模型的性能,在10个语料库上的联合试验结果优于绝大部分单独训练的模型。模型参数和超参数全部共享,复杂度不随语料库种类增长。论文:https://arxiv.org/pdf/1712.02856.pdf ;代码和语料:https://github.com/hankcs/multi-criteria-cws 。
自然语言处理,特别是中文处理中,语料库往往珍稀且珍贵。具体到中文分词,也是如此。为了做出一个实用的系统,不光需要高效的算法,大规模语料库也必不可少。然而对于缺乏经费的研究团队和个人,却往往只能得到sighan2005等屈指可数的几个小型语料库。即便如此,这些语料库的标注规范还互不兼容,无法混合起来训练(我们试验验证了这一点):
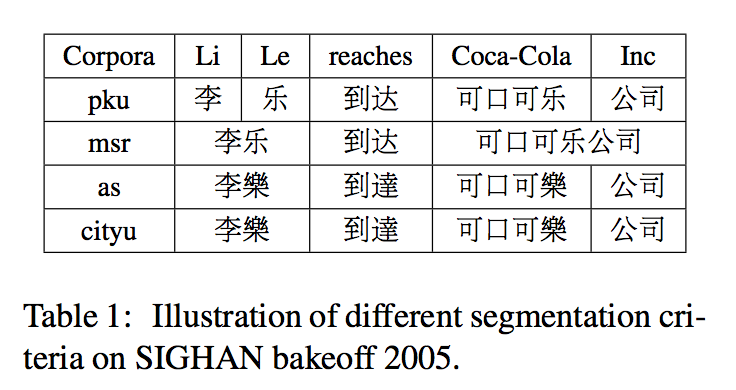
比如PKU的最大特点就是姓名拆分为“姓”+“名”,MSR的标志则是命名实体构成大量长单词,而港台地区的语言习惯本来就与大陆不同。这些差异导致无法简单合并各方语料形成一个更大量级的语料库,只能在某一个语料库上训练,浪费了其他标注数据。
已经有工作开始研究如何利用多方语料库来联合学习中文分词,比如 Chen 20171精心设计的对抗神经网络,针对每个语料库提取分词标准相关或无关的特征。然而该工作并没有达到前沿的准确率,甚至联合训练的成绩还比不上以前单独训练的分数,无法体现联合学习的本意与优势。
事实上,这些标注风格迥异的分词语料像极了机器翻译中的多国语言:表达类似的意思,却采用了不同的方式。以前的多语种互译系统也是需要针对每个语种pair设计一对encoder-decoder:
图片转自斯坦福大学CS224n讲义
对$n$种语言来讲,就需要$n\times (n-1)$对encoder-decoder。类似地,针对每个分词语料库设计网络层的话,对$n$种分词标准,就需要$n$个私有层。这样的系统臃肿不堪,过度复杂,也无法应对Zero-Shot Translation问题(缺乏某两个语言之间的平行语料)。
谷歌的解决方案说来简单,却不失优雅。聪明之处在于不修改网络架构,而是在输入数据上做文章。只需在输入平行语料pair中人工加入目标语种的标识符,就可以把所有语种的平行语料混合在一起训练了:

图片转自斯坦福大学CS224n讲义
这的确是长期跟工业生产线打交道的人才能想出来的实用方法。
受谷歌的多语种翻译系统启发,我们发现只需在句子首尾添加一对标识符,即可平滑无缝地将多标准语料库混合起来训练。具体做法是用一对闭合的<dataset> </dataset>将每个句子包裹起来:
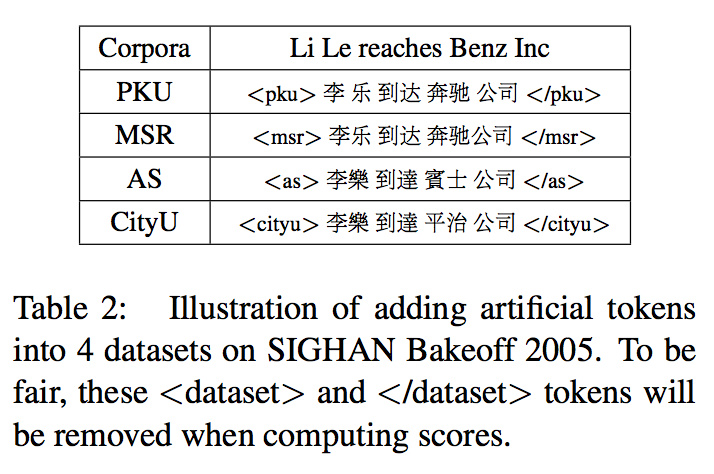
接下来就可以通过大家熟悉的Bi-LSTM-CRF等序列标注模型联合训练了。在具体联合训练中,将这两个人工标识符视作普通字符即可,也不必人工区分句子的来源。这两个人工标识符会提示RNN这个句子属于哪种分词标准,使其为每个字符生成的contexual representation都受到该分词标准的影响。
在测试的时候,这两个人工标识符起到指定所需分词标准的作用。当然,公平起见标识符并不计入准确率的计算。
代码
连同语料库一起开源在GitHub上:https://github.com/hankcs/multi-criteria-cws 。
调用脚本只需一两句话,请参考GitHub上的说明。
更多细节,请参考论文。
结果
我们在标准的sighan2005和sighan2008上做了实验,在没有针对性调参的情况下依然取得了更高的成绩(当时设备条件简陋,所以在所有数据集上都用了同一套超参数)。所有分值都通过了官方评测脚本的验算。
sighan2005
下图的baseline是在各个语料库上单独训练的结果,+naive是合并语料却不加标识符的结果,+multi是我们提出的联合训练方案的结果。

我们使用的特征是极小的,仅仅是字符和bigram。如果像最近流行的做法那样加入12个ngram、词典特征(word embedding),可能还会有进一步提升。但我们的论文中心是一个简单的多标准分词方案,主打精简高效,并非追求高分胜过效率,所以没有采用这些特征工程的手段。
sighan2008
我们也在标准的sighan2008上做了相同的试验,结果是:
值得一提的是,我们并没有针对sighan2005和sighan2008分别调参,而是放弃调参、在所有数据集上沿用了PKU的超参数。这是由于我们简陋的设备条件限制;欢迎计算力充裕的朋友自行调参,或许能有更好的结果。
10in1
由于sighan2008语料库是收费的,难以获取,没有授权的情况下也无法二次发布。同时我们不希望收费语料库成为阻碍小团队与个人研究者的壁垒,所以我们在$10$个公开的语料库上做了额外的试验。
这$10$个语料库分别是来自sighan2005的$4$份语料库以及
-
Universal Dependencies Project的UDC (Universal Dependencies Treebank Chinese)
-
由 Stanford CoreNLP 公开的 CTB6 (Chinese Tree Bank 6)
-
由山西大学发布的 SXU
-
由国家语委公布的 CNC 语料库
-
由王威廉老师公开的微博树库 WTB (Wang et al. 2014 2)
-
由张梅山老师公开的诛仙语料库 ZX (Zhang et al. 2014 3)。
语料库的授权信息如下(如有错误,欢迎反馈):
虽然部分语料库不常见于文献,但它们所属领域不同(新闻、微博、小说、港台)、数据规模迥异,恰好可以用来检验多标准分词模型的泛用性。我们的测试结果是:
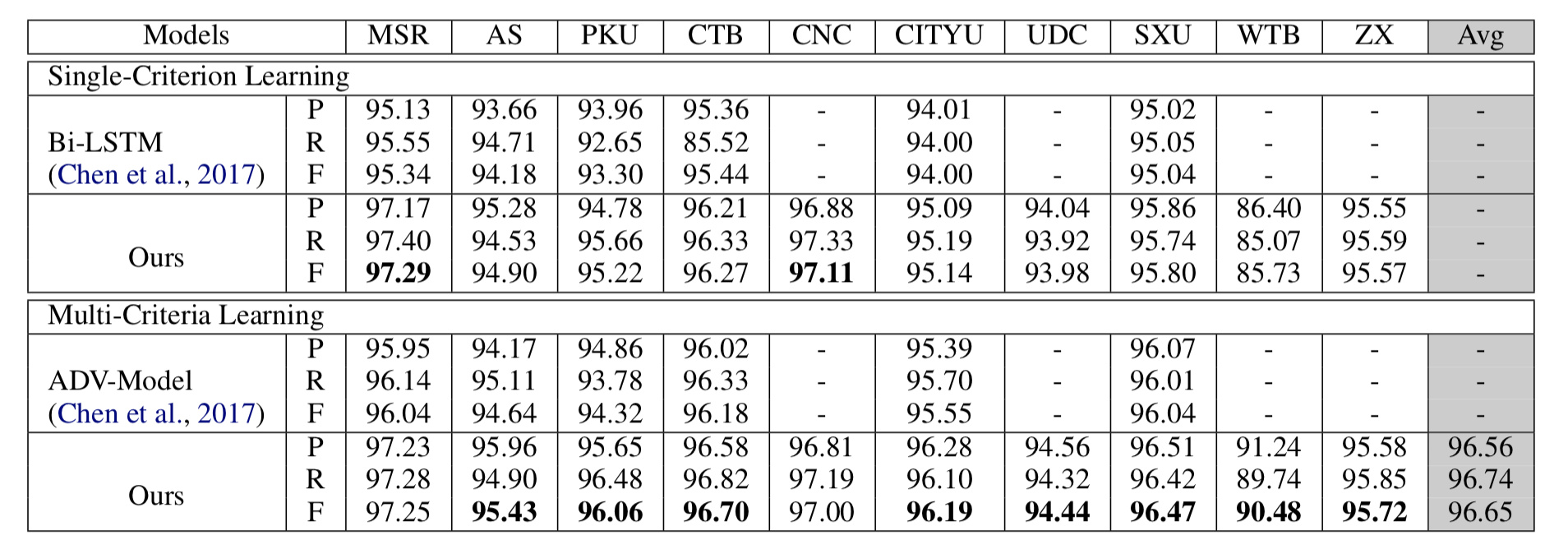
(备注:此处与 Chen 2017 无法构成直接比较)
由于RNN训练很慢,为了方便复现结果,我们提供包含随机数在内的命令行:
./script/train.sh joint-10in1 --dynet-seed 10364 --python-seed 840868838938890892
除非依赖类库版本变迁,否则应该能够保证复现我们的结果。
我们还考察了这些人工标识符所起的作用,将它们的embedding通过t-SNE可视化出来后,发现几乎没有显著的相似性:

它们似乎起的作用都不相同。
结论
这是一种简单的多标注中文分词解决方案,可以在不增加模型复杂度的情况下联合多个语料库训练单个模型。该方案虽然简单,但的确带来了显著的性能提升(特别是对于小数据集如WTB)。同时我们也注意到特别大的数据集受益很小或无法从中受益(MSR),留作未来研究。我们希望该方法成为多标准中文分词的一个baseline,或生产系统中的一个物美价廉的拓展。
这是我的第一篇NLP论文,肯定有不少错误,欢迎指出。任何语法、拼写、行文上的错误和建议,欢迎留言,我会及时更正。谢谢!
鸣谢
-
感谢在试验器材不足时伸出援手的朋友们,以及对论文和试验施以援手的同学!
-
感谢那些慷慨地公开了标注语料库的老师与研究者们,这对没有研究经费的小团队而言无疑是雪中送炭!
-
Bi-LSTM-CRF模型的实现参考了rguthrie3的Dynet1.x版本。
References
-
X. Chen, Z. Shi, X. Qiu, and X. Huang, “Adversarial Multi-Criteria Learning for Chinese Word Segmentation.,” vol. 1704, p. arXiv:1704.07556, 2017. ↑
-
William Yang Wang, Lingpeng Kong, Kathryn Mazaitis, and William W Cohen. 2014. Dependency Parsing for Weibo - An Efficient Probabilistic Logic Programming Approach. EMNLP . ↑
-
Meishan Zhang, Yue Zhang, Wanxiang Che, and Ting Liu. 2014. Type-Supervised Domain Adaptation for Joint Segmentation and POS-Tagging. EACL . ↑
您好,sighan2008的数据现在连个页面都找不到了,更别提付费购买了。。十分苦恼。。SXU数据的页面也没了。。另外CNC的链接,进去只是主页,能详细点吗?感谢回复!
你好,请问你的论文已经发表出来了吗,有什么渠道可以获取到你的论文pdf,我想读读文章看看更细节性的问题
https://arxiv.org/pdf/1712.02856.pdf
你好,请问你的论文现在已经发表出来了吗,pdf可以获取到吗。我想阅读你的论文原文,想看看更多细节问题
我在试验你的方法 出现了这个error,是因为什么呢
Traceback (most recent call last):
File “model.py”, line 528, in
loss_expr = model.neg_log_loss(instance.sentence, instance.tags)
File “model.py”, line 192, in neg_log_loss
forward_score = self.forward(observations)
File “model.py”, line 212, in forward
alphas_t.append(log_sum_exp(next_tag_expr))
File “model.py”, line 202, in log_sum_exp
return max_score_expr + dy.log(dy.sum_cols(dy.transpose(dy.exp(scores – max_score_expr_broadcast))))
AttributeError: module ‘dynet’ has no attribute ‘sum_cols’
版本不匹配,请使用DyNet v2.0
作者您好,此问题应该是这样解决的
sum_cols(x) has been deprecated.
Please use sum_dim(x, [1]) instead.
。而不是版本的问题
谢谢,做实验用的是v2.0.1,可能不会一直保持更新到最新版。
貌似tf现在也支持动态计算图了?
不太乐观,TensorFlow Fold is not an official Google product,几个月没更新了
请问您代码中用的一种dynet神经网络框架,这个框架相比tensorflow优势在哪
Dynet是动态神经网络的缩写,能够为每个训练实例动态声明不同的网络结构。不同于TF、mxnet等静态声明策略,Dynet允许以自然的编程语句隐式声明计算图,符合正常编程思维。另外,Dynet在CPU上的执行速度非常快,我记得单线程的速度比TF多线程还快。这篇论文做实验的时候,我甚至能在多核机器上同时跑多个实验。
了解了,谢谢