目录
 随着深度学习的普及,有越来越多的研究应用新模型到中文分词上,让人直呼“手快有,手慢无”。不过这些神经网络方法的真实水平如何?具体数值多少?以Sighan05中的
随着深度学习的普及,有越来越多的研究应用新模型到中文分词上,让人直呼“手快有,手慢无”。不过这些神经网络方法的真实水平如何?具体数值多少?以Sighan05中的PKU数据集为例,真像一些论文所言,一个LSTM-CRF就有96.5%吗?或者像某些工业界人士那样,动辄“基于深度学习的98%准确率”,“99% 的分词成功率”吗?
如果数字真的这么好看,那中文分词这个课题几乎没有研究意义了。更何况,中文分词标准难以统一,任何语料库都存在内部标注一致性(inter-annotator agreement)的问题。一些著名的语料库(如CTB)设有质量检测机制1,虽然没有公布具体内部标注一致性数值,但Shen 20162抽样重新标注校验的CTB5在分词上的一致性才达到99.10%;可据此推测CTB的内部一致性低于99%。而其他著名语料库(如PKU、MSR等)则既没有公布一致性数值,也没有人做相关试验。国家语委语料库则简单地说了句“标注是指分词和词类标注,已经经过3次人工校对,准确率大于>98%”3;综合学术界穷极特征工程与语言学资源(词典)的分词器不超过98%的分值这一事实来保守估计,这些语料库的一致性不会超过98%。而PKU分值几乎没有超过96%的,所以任何声称在PKU上拿到97%以上所谓“准确率”的说法,可信度都不高。
本文收集分析一些可信的state of art数据,尝试还原当前(2017年左右)中文分词的真实面貌。联想到最近的造假事件,试验最基本的要求是一定要保证可复现。一切观点都应该以可复现的试验数值支撑,数值来源需满足:
-
在公开合法的语料库上试验
-
坊间流传的泄露版人民日报2014不在此列
-
该语料疑似机器分词,没有经过人工校对,错误百出
-
实现代码开源
-
闭源商业实现不予考虑
-
还需开源训练模块
-
试验过程规范
-
训练集、开发集、测试集的拆分符合convention
-
无“在测试集上调参”的操作
满足这些条件的,基本只剩顶会paper了。本文权当一份中文的调查报告吧。虽然盲从是无知的体现,质疑和批判是治学的良方;但作者水平实在有限,恐有谬误,也欢迎随时质疑批判。
旧时代的阴影
归功于传统特征工程时代人们的费尽心机,以至于早期(2014年左右)的神经网络方法根本无法与特征工程匹敌。当时有篇Pei 20144算是较早的一批之一,其中讲到
the study of deep learning for NLP tasks is still a new area in which it is currently challenging to surpass the state-of-the-art without additional features.
也算是一个精辟的总结吧。
Pei 2014的模型与Zheng 20135相同,就是一个Window Based NN分类器:
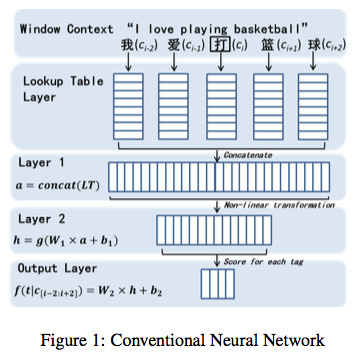
然后加入了bigram feature,利用the average of character embeddings of $c_k$and $c_{k+1}$初始化,利用Max-Margin作为损失函数。
不加bigram特征时相较于以前的工作推进了一个百分点:
他们无法与特征工程对抗,那就顺从特征工程,也加几个特征呗。
A very common feature in Chinese word segmentation is the character bigram feature.
加了bigram特征后,与传统特征工程终于comparable了:
我挺喜欢这张表格的,其中2013年之前的都是非NN传统方法。可见截止2014年的时候,NN方法没有取得显著成绩。
sequence模型
虽然RNN with LSTM extension早在1997年就提出了,但真正进入人们视野应该得益于谷歌Sutskever 2014 6这篇论文。于是2015年的时候,RNN sequence model被应用到各种sequence标注任务上。
Chen等人速度的确很快,在2015年一举拿下GRU和LSTM7两篇论文,其中LSTM的试验效果比GRU要好,成为LSTM-CWS的代表作。LSTM最大的优点就是理论上无限大的“window”,或说上文吧;以及实际约200个time step左右的记忆跨度。他们举了个很好的例子:
冬天 (winter),能 (can) 穿 (wear) 多少 (amount) 穿 (wear) 多少 (amount);夏天 (summer),能 (can) 穿 (wear) 多 (more) 少 (little) 穿 (wear) 多 (more) 少 (little)。
没有脱离window
Chen等人虽然引入了LSTM,但并没有脱离window模型的桎梏。他们的LSTM单元的输入是相邻字符的window:

这一点其实也有实际的考量,因为window based方法实在成果斐然,我试验用感知机信手实现一个基线模型,窗口大小仅为2就能在MSR上拿到96.3的F1。这说明中文分词其实不需要多大的上下文,或者说远处的字符对当前字符的影响微乎其微。但这又与LSTM的长处相抵触,Chen等人又认为要分对上述“冬夏”的例子,必须有一个很大的上下文。这可能是论文的一个矛盾之处。另外,LSTM只有上文,引入字符window可以带来下文,这可能能够解释一部分矛盾。
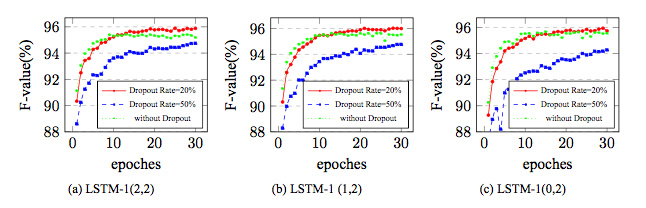
果然,Chen等人的试验也证明0个字符上文2个字符下文的LSTM窗口效果最好:
无法脱离特征工程
虽然是NN方法,但他们也无法脱离特征工程。其中,
-
char window本身已经是一种特征
-
还加入了Pei 2014引入的bigram特征
他们的最终成绩如下:
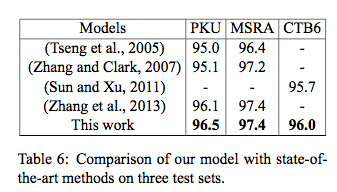
96.5的分值的确是超越了以往工作,论文行文也非常清晰,我个人非常喜欢。
预处理引发争议
但是Chen等人对数据的预处理存在非常大的争议:
All datasets are preprocessed by replacing the Chinese idioms and the continuous English characters and digits with a unique flag.
英文字母和数字的替换并无不妥,争议发生在“中文习语”的替换上,用词典替换测试集中较长的词语实在无法认同。Cai 20168对此吐槽颇多:


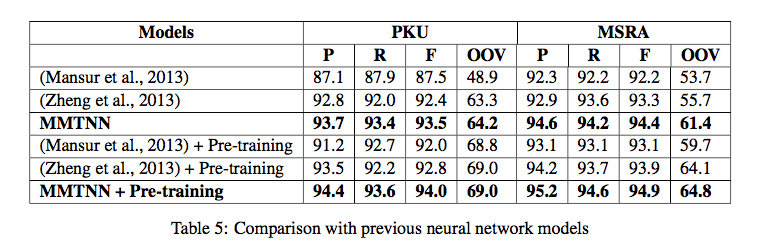
这种做法导致Cai等人不得不自己重新跑一遍Chen等人的代码(去掉词典):
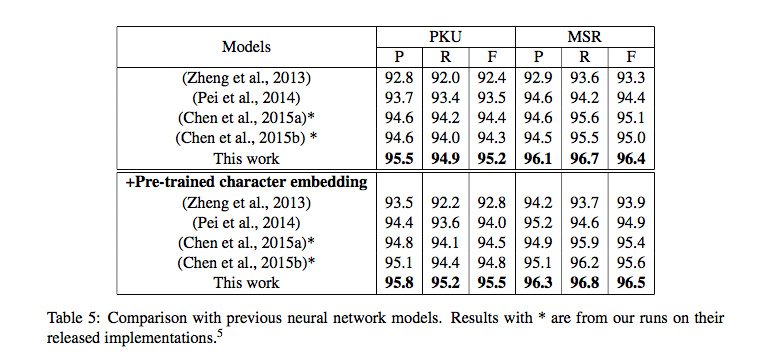
上表加星号的可视作无词典情况下Chen 2015的真实分值,其中PKU的分值为94.8,与挂载词典的96.5差距极大!
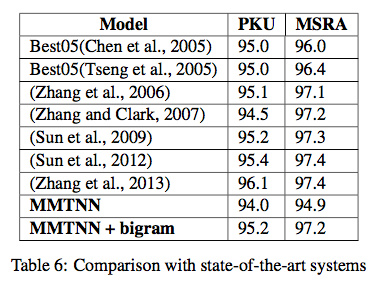
Cai等人后来自己也挂了一个词典,得到如下实验结果:
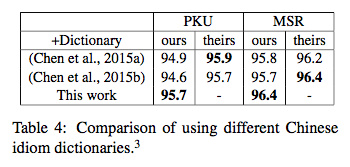
Cai的最终分数如下:
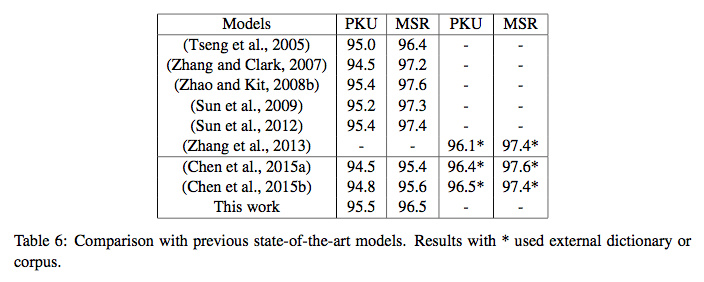
加星号的都外挂了词典,Zhang和Chen都来自复旦大学,也算是一种流派吧。
另外,Chen本人在ACL 20179上的论文也坦言:
although the F value of LSTM model in (Chen et al.(2015b)Chen, Qiu, Zhu, Liu, and Huang) is 97.4%, they additionally incorporate an external idiom dictionary.
算是承认了这一争议吧。
之后还有Yao 2016的Bi-LSTM-CWS,由于没有公开源码,所以不做表态。(另,该文将SIGHAN bakeoff误拼写为SIGHAN Backoff,给人第一印象就十分地不严谨。)
Word-based Methods
刚才介绍的Cai 20168独树一帜,跳出了序列标注的框框,直接对分词结果建模。他们的动机是,之前的方法无论用了多好的NN,实际上都是基于窗口的:

而他们想完全消除窗口,直接对分词结果建模。分词结果的好坏由下列两个方面衡量:
-
每个单词成词的分数
-
单词接续的分数
单词打分
枚举定长$L=4$之内的所有单词,用GCNN(Gated Combination Neural Network)
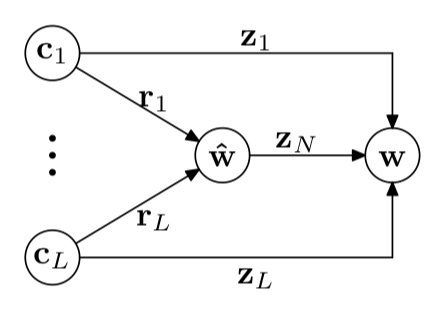
组合,得到词语向量
$$\begin{equation}
\nonumber
\mathbf{w}=\mathbf{z}_N\odot \mathbf{\hat{w}}+\sum_{i=1}^{L}\mathbf{z}_{i}\odot \mathbf{c}_i
\end{equation}$$
与一个参数向量内积得到词语分数:
$$\mathrm{Word\_Score}(\mathbf{y}_i) = \mathbf{u}\cdot\mathbf{y}_i$$
link打分
用LSTM将分词历史agglomerate起来:
$$\mathrm{Link\_Score}(\mathbf{y}_{t+1}) = \mathbf{p}_{t+1}\cdot\mathbf{y}_{t+1}$$
分词结果得分
就是单词得分与句子得分之和:
$$\begin{equation}\label{sentence_score}
s(y_{[1:n]},\theta) = \sum_{t=1}^{n}(\mathbf{u}\cdot\mathbf{y}_t+{\mathbf{p}_t}\cdot\mathbf{y}_t)
\end{equation}$$
训练与解码
这类概率无关的模型一般就 max-margin 了,解码的时候有些技巧。由于所有可能的分词序列是指数级,所以必须beam search。另外作者在ACL1710上改进了算法,贪心搜索就行了。
其实,由于限制了最长单词为4,所以实际复杂度并不高。
质疑
虽然我很喜欢这篇独辟蹊径的论文,以及作者仗义执言的个性,但作者的数据预处理依然存在争议,在他们公布的代码中,将测试集中长度大于4的单词都处理为了字母L:
if len(word)>Maximum_Word_Length: count+=1 longwords.append(word) ... if word in longws: count_longws+=1 word = u'L'
举例如下:
| 原测试集 | 处理后 |
|---|---|
| 来 促进 发展中国家 的 发展 | 来 促进 L 的 发展 |
| 气势 恢宏 的 柴可夫斯基 | 气势 恢宏 的 L |
| 农村 实行 生产责任制 后 | 农村 实行 L 后 |
| 在 四通利方公司 的 实验室 里 | 在 L 的 实验室 里 |
虽然Cai的模型的确将最长长度视作超参数,但也不能说因为模型无法处理这些单词,所以把它们从测试集中抹掉啊。“柴可夫斯基”“四通利方公司”是命名实体,不是Chen所说的idiom,怎么能说去掉就去掉呢?Cai等人的95.8里面依然存在水分。
Multi-Criteria Joint Learning
就是利用多个分词标准的语料库联合训练,前面也提到过,ACL 2017上Chen等人的最新工作。已经有一些优秀的文章介绍了这份工作,但本文更关注现有工作的不足。
Chen 2017将所有繁体语料按字转换为简体,任何写过或者用过高级一点的简繁转换工具的人都会摇头,因为简繁并非是按字一一对应的。比如“以後等妳當上皇后”中的两个“后”字,以及大陆的“代码”、台湾的“程式碼”、香港的“代碼”甚至连字符数都不相同。按字转换本身就十分地不符合语言学观点,哪怕对分值来讲无关紧要。
另外,模型依然没有脱离窗口,还在利用bigram feature:
all experiments including baseline results are using pretrained character embedding with bigram feature.
最重要的一点是,引入GAN到中文分词这么简单的任务(相较于句法分析、机器翻译而言)上来实在是大材小用。论文多个private的LSTM layer和CRF layer显得过度设计,过于复杂。更何况最终分值相较于以前的工作并没有多少进步:
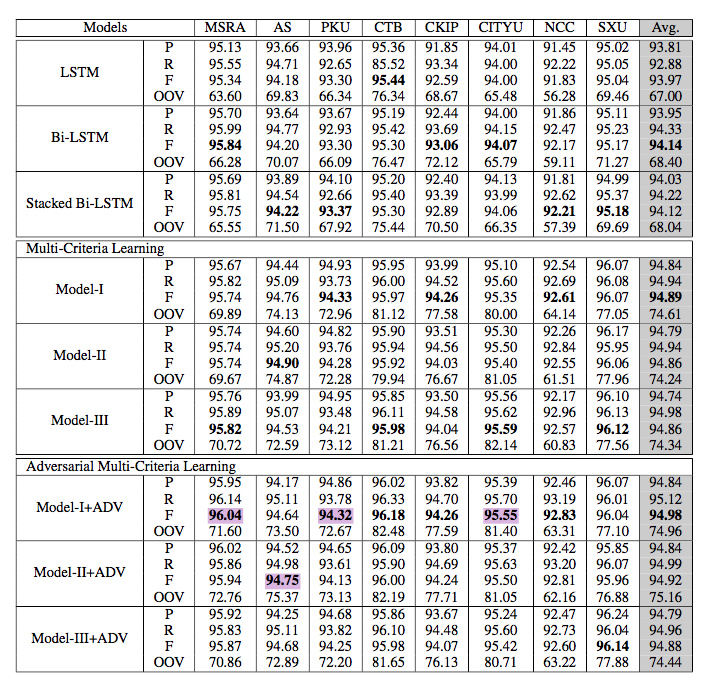
一般而言,关联度非常高的联合任务应当取得显著的分值提升才对。Chen 2017只与自己做比较,未与其他state of art工作做比较,显得对Multi-Criteria Joint Learning信心不足,也没有挖掘出Multi-Criteria Joint Learning的真实潜力。
我的实验
我依然非常喜欢Chen等人的这篇论文,因为它设置了一个很棒的baseline。我在7月中旬开始了Joint Learning相关试验,现在已经在sighan05上已经取得了超过今年ACL上Chen 2017的分数:
P R F1 pku 95.28 96.01 95.64 msr 96.20 96.43 96.31 as 95.68 95.00 95.34 cityu 96.00 95.87 95.94 AVG 95.75 95.78 95.77
其中cityu的分值已经超越了今年ACL上Cai 2017的95.6,as已经达到95.3,这些分值还在随着模型改进与超参数调整而提升中,估计再调调可以在更多dataset上超越state of art。
现在遇到的问题是:
-
试验设备有限
-
我只有一台MBP、一台杂牌组装机、一台Intel(R) Xeon(R) CPU E3-1220 v5 @ 3.00GHz的塔式服务器
-
三台机器同时开工,天气炎热,风扇噪音不堪忍受;好些天没睡过一个好觉
-
没有GPU
-
语料有限
-
我只有sighan05的4份语料,没有sighan08以及CTB的语料
-
如果有Chen 2017相同的8份语料,则会更有说服力
-
虽然增加语料,joint model的分值不一定提升,但我个人非常有信心
-
没有合著者
-
身边没有研究中文分词的师长
-
缺乏论文指导老师
我将会在近日将论文$\LaTeX$草稿上传arXiv,代码上传GitHub,欢迎到时候批评指正,也欢迎手头有富余计算资源、实验室有sighan08语料、希望合著这篇论文、指导论文的同学和学者老师联系我;我目前人在国内,可以签字一切必要的授权文档。
感谢大家的帮助,试验顺利做完,论文已经投出。水平实在有限,加之缺乏指导、没有Sighan08语料,所以难登大雅之堂。只不过提出了一种简单的多语料训练方案而已,在模型上没什么新意,请不要过于期待。唯一能保证的就是,数据真实可复现吧。这段时间还另外做了一些尝试(偏旁部首拆字分词,ID-CNN分词),preprint和代码都会逐步公开,欢迎批评指正。
这份调研还有很多优秀工作没有涉及到,比如张梅山老师的Sparse Feature与Transition-Based方法等。
初次涉足NLP学术界,不胜惶恐,同时又实在需要帮助;谬误肯定不少,欢迎批评指正,谢谢!
References
-
N. Xue, F.-D. Chiou, and M. S. Palmer, “Building a Large-Scale Annotated Chinese Corpus.,” COLING, 2002. ↩
-
M. Shen, W. Li, H. Choe, C. Chu, D. Kawahara, and S. Kurohashi, “Consistent Word Segmentation, Part-of-Speech Tagging and Dependency Labelling Annotation for Chinese Language.,” COLING, 2016. ↩
-
http://www.cssn.cn/yyx/yyxcyzy/201509/t20150922_2423182.shtml ↩
-
W. Pei, T. Ge, and B. Chang, “Max-Margin Tensor Neural Network for Chinese Word Segmentation.,” ACL, 2014. ↩
-
X. Zheng, H. Chen, and T. Xu, “Deep Learning for Chinese Word Segmentation and POS Tagging.,” arXiv, 2013. ↩
-
I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to Sequence Learning with Neural Networks.,” NIPS, 2014. ↩
-
X. Chen, X. Qiu, C. Zhu, P. Liu, and X. Huang, “Long Short-Term Memory Neural Networks for Chinese Word Segmentation.,” arXiv, 2015. ↩
-
D. Cai and H. Zhao, “Neural Word Segmentation Learning for Chinese.,” ACL, 2016. ↩
-
X. Chen, Z. Shi, X. Qiu, and X. Huang, “Adversarial Multi-Criteria Learning for Chinese Word Segmentation.,” arXiv, vol. 1704, p. arXiv:1704.07556, 2017. ↩
-
D. Cai, H. Zhao, Z. Zhang, Y. Xin, Y. Wu, and F. Huang, “Fast and Accurate Neural Word Segmentation for Chinese,” arXiv.org, vol. cs.CL. p. arXiv:1704.07047, 24-Apr-2017. ↩
支持一下,很反感盲目堆网络,靠超参预处理做出来的效果,想想都知道泛化能力低到令人发指
感谢分享!现在有个需求:匹配出一段文字中的“违禁词(和谐词)”。
我的思路是使用您的HanLp进行分词,之后直接2个set进行hash比对,不知有何高见?
是否HanLp在分词的基础上,额外增加一个对指定子词库(比如违禁词)匹配
大神,我在学习HanLP的代码。观察目前主要是5个分词器(CRF/Dijkstra/HMM/NShort/Viterbi)。您觉得,文章中提到的基于深度学习的分词算法,相比HanLP实现的几类分词器,有哪些优点和缺点呢?
赞!自己没有GPU机器的话,建议试试google云,只要绑定信用卡就免费送300刀额度,升级一下账号就可以用GPU了,按量扣费,跑完任务就停机,300刀跑非工业任务可以用上一阵子了。
我最近也在关注分词,手头有Titan xp,有需要可以联系我
感谢帮助,试验顺利写完,论文已经投出。水平实在有限,加之缺乏指导,所以难登大雅之堂,请不要过于期待。无论多初级的期刊会议,一旦录用,preprint和代码都会即时公布,欢迎批评指正。
最近也在研究这篇论文,实验室有多块空闲的K40和Titan Xp,希望能一起交流
感谢帮助,忙了一阵,试验顺利做完,论文已经投出。水平实在有限,加之缺乏指导,所以难登大雅之堂,请不要过于期待。无论多初级的期刊会议,一旦录用,preprint和代码都会即时公布,欢迎批评指正。
最近也在做中文分词,对分词有一定对了解,有各种分词数据集,也有gpu服务器,有兴趣可以合作。
谢谢,已发邮箱。
赞!从大神博客学到了很多东西,我们实验室有几块Titan X,如果能帮上忙可以联系我的邮箱。
谢谢!真是雪中送炭,已经发你邮箱了。
王女大人,爱死你了
求作者论文地址和代码github地址
感谢帮助,忙了一阵,试验顺利做完,论文已经投出。水平实在有限,加之缺乏指导,所以难登大雅之堂,请不要过于期待。无论多初级的期刊会议,一旦录用,preprint和代码都会即时公布,欢迎批评指正。
找个R&D也行啊
为什么不去找老师和实验室呢?
感谢帮助,忙了一阵,试验顺利做完,论文已经投出。水平实在有限,加之缺乏指导,所以难登大雅之堂,请不要过于期待。无论多初级的期刊会议,一旦录用,preprint和代码都会即时公布,欢迎批评指正。
更新了,nice