当分词系统有一份词典的时候,就可以生成词图了。所谓词图,指的是句子中所有词可能构成的图。如果一个词A的下一个词可能是B的话,那么A和B之间具有一条路径E(A,B)。一个词可能有多个后续,同时也可能有多个前驱,它们构成的图我称作词图。
词图的生成
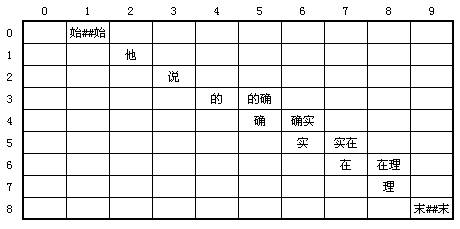
需要稀疏2维矩阵模型,以一个词的起始位置作为行,终止位置作为列,可以得到一个二维矩阵。例如:“他说的确实在理”这句话
那么如何建立节点之间的联系呢?也就是如何找到一个词A的后续B、C、D……呢?有两种已实现的方法,一种是所谓的DynamicArray法,一种是快速offset法。
DynamicArray法
最直截了当的想法当然是用二维数组模拟这个模型了,很明显,其中有不少空洞,所以在ICT系列的分词器中定义了一个蹩脚的DynamicArray结构用来储存模型,DynamicArray结构的每个节点包含一个个词的row和col,待会儿看完offset法你就会明白我什么么说DynamicArray蹩脚。
在这张图中,行和列有一个非常有意思的关系:col为 n 的列中所有词可以与row为 n 的所有行中的词进行组合。例如“的确”这个词,它的col = 5,需要和它计算平滑值的有两个,分别是row = 5的两个词:“实”和“实在”。
连接词形成边的时候,利用上面提到的关系即可。
但是在遍历和插入的时候,需要一个个比较col和row的关系,复杂度是O(N)。
快速offset
虽然模型的表示用DynamicArray没有信息的损失,但问题是,真的需要表示模型吗?
当然不,我可以将起始offset相同的词写到一行:
始##始 他 说 的/的确 确/确实 实/实在 在/在理 理 末##末
这个储存起来很简单,一个一维数组,每个元素是一个单链表。
怎么知道“的确”的下一个词是什么呢?“的确”的行号是4,长度是2,4+2=6,于是第六行的两个词“实/实在”就是“的确”的后续。就这么简单。
同时这种方法速度非常快,插入和查询的时间都是O(1)。
小结
MISS是设计的准则,不需要新定义那么复杂的数据结构。ICT作者为何定义那么复杂的DynamicArray,写了那么多曲曲折折的代码就不知道了。
Reference
http://www.cnblogs.com/zhenyulu/articles/668035.html
http://blog.csdn.net/sinboy/article/details/663123
请问offset这个参数是什么,有什么作用?
当调用标准分词的时候,并且在用户自定义词典加入了新词。在对一个包含分词的句子进行分词时,分词系统是采用什么样的分词策略啊?我的理解时标准分词是叠层隐马尔科夫最短路,自定义词典是ac+trie。请问一下是怎么处理的啊?
2元语法词典路径,是用来模拟马尔可夫的转移概率么? 这个词典也太大了吧,有什么简便的方法可以处理么?
在所有模型里算小的,HanLP有独特的压缩方法
看楼主源码,为什么你自己写的最短路方法,叫Viterbi算法,我没有看出来
你好
不一致,是在句子中的offset
不是,最短路是概率负对数图的最短路
不清楚,它那个应该是落后的词典分词
how are you thank you
0-3 4-7 8-11 12-17 18-21 offset,
楼主你好,请教几个问题:
1.说和确/确实,两个term的起始位移不一致吗,不都是0吗?
2.的确”的行号是4,长度是2,4+2=6,于是第六行的两个词“实/实在”就是“的确”的后续。这就是所谓的最短路径算法?
3.lucene smartcn的最短路径算法就是您的第二种?
请问这么一个CoreNatureDictionary.ngram.** 的词典是如何生成,在您开源的hanlp中对应哪个代码?
训练出来的,这里的main方法就演示了核心词典、BiGram词典、词性转移矩阵的生成。当然,你得自己准备一个分词语料库。http://t.cn/R2aIgJh
标准分词就是ICTCLAS分词系统吧??
可以这么说,基于层叠隐马模型的最短路分词
这里的词图的生成就是标准分词的解释吗?
对
你这里所说的:标准分词就是前向最大匹配方法吗?
不是
呵呵,我就是这么实现的。