最近在看Ansj中文分词的源码,以前没有涉足过这个领域,所以需要做一些笔记。
2015年4月13日更新
经过研究与试验,我觉得trie树分词是一种很落后的技术。
最完美的分词、停用词过滤的技术是Aho Corasick自动机结合DoubleArrayTrie极速多模式匹配。
AhoCorasickDoubleArrayTrie能够以每秒2000万字的速度实现分词和过滤,是trie树的10倍,传统AC自动机的4倍。
我基于AhoCorasickDoubleArrayTrie和DoubleArrayTrie开发了开源的Java分词器HanLP,训练自2014年人民日报语料,支持并行化分词等。下载地址:http://www.hankcs.com/nlp/hanlp.html
Trie树
首先是Ansj分词最基本的数据结构——Trie树。Trie树也称字典树,能在常数时间O(len)内实现插入和查询操作,是一种以空间换取时间的数据结构,广泛用于词频统计和输入统计领域。
Ansj作者ansjsun为此数据结构专门开了一个项目,clone下来之后可以用作者提供的一个demo进行测试:
package com.hankcs;
import love.cq.domain.Forest;
import love.cq.library.Library;
import love.cq.splitWord.GetWord;
import java.io.BufferedReader;
import java.io.StringReader;
/**
* @author hankcs
*/
public class Main
{
public static void main(String[] args) throws Exception
{
/**
* 词典的构造.一行一个词后面是参数.可以从文件读取.可以是read流.
*/
String dic =
"中国\t1\tzg\n" +
"人名\t2\n" +
"中国人民\t4\n" +
"人民\t3\n" +
"孙健\t5\n" +
"CSDN\t6\n" +
"java\t7\n" +
"java学习\t10\n";
Forest forest = Library.makeForest(new BufferedReader(new StringReader(dic)));
/**
* 删除一个单词
*/
Library.removeWord(forest, "中国");
/**
* 增加一个新词
*/
Library.insertWord(forest, "中国人");
String content = "中国人名识别是中国人民的一个骄傲.孙健人民在CSDN中学到了很多最早iteye是java学习笔记叫javaeye但是java123只是一部分";
GetWord udg = forest.getWord(content);
String temp = null;
while ((temp = udg.getFrontWords()) != null)
System.out.println(temp + "\t\t" + udg.getParam(1) + "\t\t" + udg.getParam(2));
}
}
输出:
中国人 null null 中国人民 null null 孙健 null null 人民 null null CSDN null null java学习 null null java null null
这段demo的目的是利用一个小词典对后面一句话进行分词,词典被用来构造了一颗Trie树,也就是代码中的forest。
词典每一行第一列是单词,之后的几列都是param(属性)。
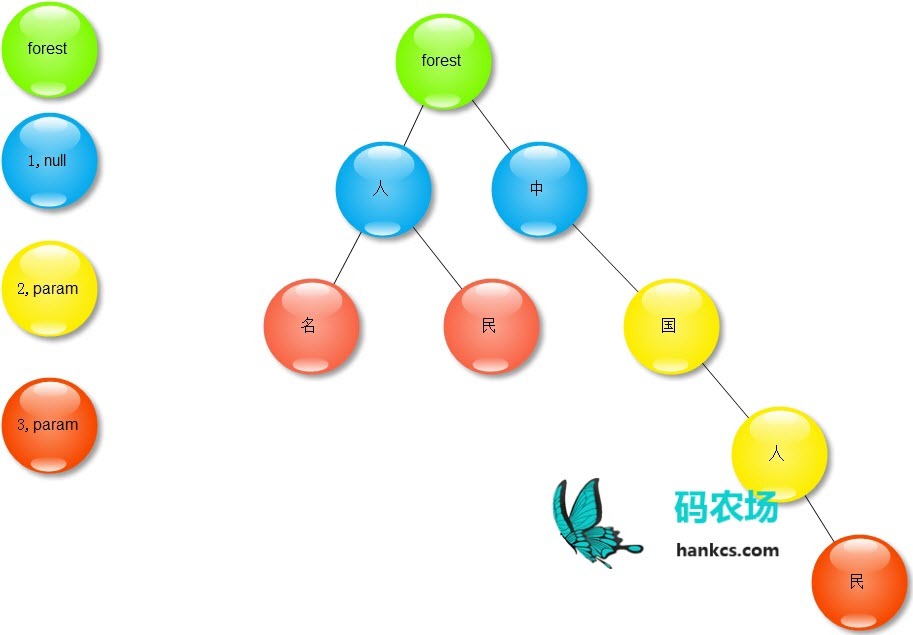
在tree_split中,一棵Trie树有四种不同的节点:
-
根节点,上图的绿色节点。被称为Forest,没有实际含义,也不含属性。
-
起始节点,上图的蓝色节点。是一个单词的开头第一个字,不含属性。
-
中继节点,上图的黄色节点。是一个单词的结尾,含属性;同时是另一个更长的单词的中间某个字,不含属性(节点的属性不代表这个长单词的属性)。
-
结束节点,上图的红色节点。是一个单词的结尾,含属性。
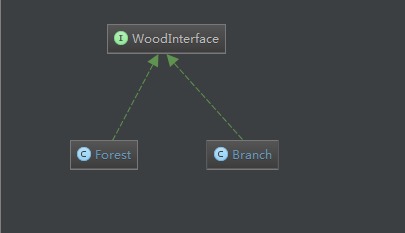
根节点使用Forest描述,而其它三种节点统一使用Branch描述,并用status = 1 2 3 来区分,它们有如下的类图关系:
Root在构造的时候开了212个空槽以供放置子节点,每个汉字和其他字符都落在这个范围内。每次查找直接用汉字作为下标即可定位,Branch则使用动态数组分配内存,使用二分查找定位,这是Trie树的高速秘诀。Trie树的查询和插入都是类似的方法:从根节点开始沿着词语的开头字符走到结尾字符。在这里除了完成基本的维护操作,还需维护Branch的status。
删除操作比较讨巧,统一将要删除的单词最后一个字对应的节点设为“起始节点”,那么它就不能构成这个词了。
词典分词
词典分词是一种实现简便、速度快但是错误率高的分词方式。用Trie树词典分词就是按照句子的字符顺序从root往下走,每走到一个结束节点则分出一个词。中途遇到的中继节点统统忽略,这种方式也称“最长匹配”,是一种很武断的方式。比如下面这个例子:
package com.hankcs;
import love.cq.domain.Forest;
import love.cq.library.Library;
import love.cq.splitWord.GetWord;
import java.io.BufferedReader;
import java.io.StringReader;
/**
* @author hankcs
*/
public class Main
{
public static void main(String[] args) throws Exception
{
/**
* 词典的构造.一行一个词后面是参数.可以从文件读取.可以是read流.
*/
String dic =
"商品\t1\tzg\n" +
"和服\t2\n" +
"服务\t4\n" ;
Forest forest = Library.makeForest(new BufferedReader(new StringReader(dic)));
String content = "商品和服务";
GetWord udg = forest.getWord(content);
String temp = null;
while ((temp = udg.getFrontWords()) != null)
System.out.println(temp + "\t\t" + udg.getParam(1) + "\t\t" + udg.getParam(2));
}
}
输出:
商品 zg null 和服 null null
很明显,效果不好。
要想提高分词效果,就必须引入条件概率(隐马尔可夫模型),这就是Ansj分词的使命吧。
结果还是不太理想, 具体分割为35M 的小字典, 一共27个, 生成的每个 .bin大概为90M 左右,然后加载到内存大概占150-200M,本机机器加载到中间就OM了。 是不是不是线性增长的呢?
dat为了解决冲突留了很多空洞,词典越大空洞越多。小个词典如果依然不理想就只有换个数据结构,collection包下面有个doublearray,是另一个省内存的dat,你可以试试
博主太耐心了!再点个赞 。目前词典大小是固定的就是35M, 我现在在本地debug的时候,加载了11个35M的小模型bin, 开了2G内存的JVM,挺流畅的,目前来看是线性的,而且加载90M的bin 很快,大概1-2S; 不过又有了新的问题。。。[衰] 有一些在字典的词语, 不能识别,这个 正常吗? 还是只要是加载了字典,就会识别出来,而不是拆开?或是我生成的DAT 本地文件有问题? [给力]
基于统计模型的分词器不保证用户词一定被切分出来。
OK, 明白了, 再次感谢您耐心的回复指导 [给力] , 作为一名学生党 向你学习![good]
结果还是有问题, 具体分割为35M 的小字典, 一共27个, 生成的每个 .bin大概为90M 左右,然后加载到内存大概占150-200M, 这个结果是不是线性的呢? 就是说,需要5-6G的内存就可以加载完全。
这个样子,实在不行,就只能split 字典,使用一部分了; 修改您的trie树结构,恐怕有点困难– 之前只用trie树水过几道oj题目
这样可以减小dat的内存,但总体应该是比bin-trie多的,如果bintrie都装不下,那这个方法应该也不行
再次感谢楼主耐心的解答! 现在已经知道多个词典会汇总为一个bin了,此路不通了; 现在是打算设置多个dat,分别加载多个词典的bin。在分词的时候,去遍历dat,直到找到匹配,或者结束。这个是基于:加载两个100M的字典的消耗,是小于 直接加载一个200M的字典的,您看这样适合解决大字典的问题吗?
把status去掉,value换成byte,你需要理解trie算法。
不行,多个词典会汇总成一个bin的。
不好意思 博主,再来打扰您! 您看这样有效吗?我把900M的字典分割成多个小一点的文件,然后在以文件的形式加载自定义字典, 这样就他可以生成缓存.bin 文件, 下次就直接加载这多个 .bin 文件,您看这样可行吗?
ok 好的,麻烦您了! 继续学习一下,我的字典里面只有一个属性 就是一些地名,您看在优化上,有什么建议吗? 🙁 实在是麻烦您了
900mb太多了,如果连一行行的add都不行,那只有再想办法优化trie树了,节点里面有些field可以优化掉
刚刚又看了一点源码,明白您说的意思了,就是,我修改配置文件,加载自定义字典,然后存到dat变量中的耗内存比 我读取字典文件,一行行的add,更多内存,是这个意思吧? 那我应该怎么能够把900M的字典加进去呢? 加载时间暂时不考虑,但是总出现 out of memrry的问题,我机器8G内存的, 谢谢解答!
感谢及时回复! 能不能详细一点,看不太懂您说的; 就是我直接把字典文件 写到配置文件里面,这样可以吗? 因为我使用读取字典,然后一条条词语加的话,会出异常,您的意思是就是把字典文件写入到配置文件里面吗?
你好,通过文件加载的词条存在dat里面,dat占内存更多。
博主您好,我先问一下 , 使用CustomDictionary.add(raw_text, defaultNature); 来添加用户自定义字典的时候, 字典大小有没有限制,我有一个几百M 的 词典,为什么加载不进去呢?