《Lucene实战(第2版)》 配书代码的下载地址点此,解压后得到lia2e目录,编译运行方法有两种:
最基础的Ant编译:
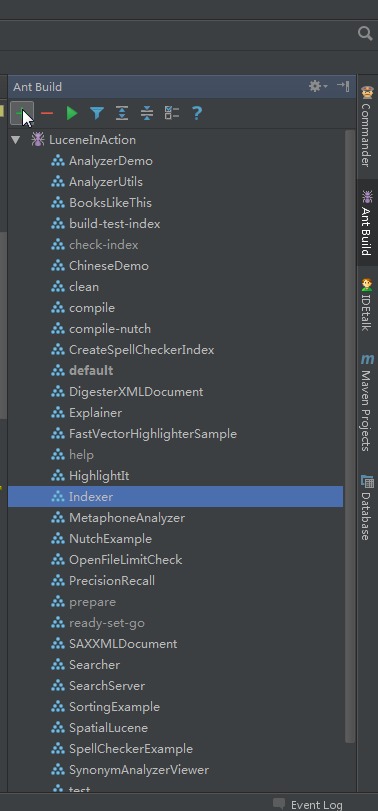
点击右边的加号载入lia2e下的build.xml脚本,接着在列表里双击某单元对应的程序就行了:
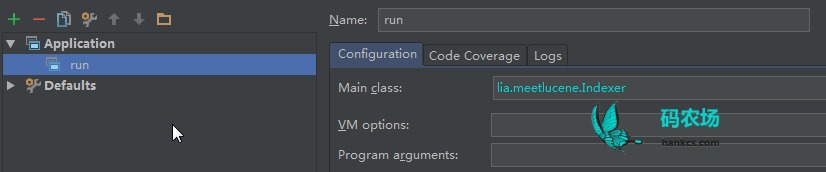
通过IDEA Configuration编译运行:
新建一个控制台配置,选择主类:
编译运行报错:
java: 找不到符号
符号: 方法 next()
位置: 类型为org.apache.lucene.analysis.TokenStream的变量 ts
这是因为lia/analysis/nutch/NutchExample.java需要使用Lucene 2.4.0,但是配书代码用的是3.0:
<!– Nutch uses Lucene 2.4.0, but the rest of the sources use 3.0.0,
so we set up a separate compile target & classpath –>
解决方案是注释掉NutchExample,在第四章要用到的话再改回了来用Ant编译。
接下来编译成功,运行出错:
Exception in thread "main" java.lang.IllegalArgumentException: Usage: java lia.meetlucene.Indexer <index dir> <data dir>
at lia.meetlucene.Indexer.main(Indexer.java:41)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:120)
少了两个参数而已,改成:
package lia.meetlucene;
/**
* Copyright Manning Publications Co.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific lan
*/
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.Directory;
import org.apache.lucene.util.Version;
import java.io.File;
import java.io.FileFilter;
import java.io.IOException;
import java.io.FileReader;
// From chapter 1
/**
* This code was originally written for
* Erik's Lucene intro java.net article
*/
public class Indexer {
public static void main(String[] args) throws Exception {
args = new String[2];
args[0] = "indexes/MeetLucene";
args[1] = "src/lia/meetlucene/data";
if (args.length != 2) {
throw new IllegalArgumentException("Usage: java " + Indexer.class.getName()
+ " <index dir> <data dir>");
}
String indexDir = args[0]; //1
String dataDir = args[1]; //2
long start = System.currentTimeMillis();
Indexer indexer = new Indexer(indexDir);
int numIndexed;
try {
numIndexed = indexer.index(dataDir, new TextFilesFilter());
} finally {
indexer.close();
}
long end = System.currentTimeMillis();
System.out.println("Indexing " + numIndexed + " files took "
+ (end - start) + " milliseconds");
}
private IndexWriter writer;
public Indexer(String indexDir) throws IOException {
Directory dir = FSDirectory.open(new File(indexDir));
writer = new IndexWriter(dir, //3
new StandardAnalyzer( //3
Version.LUCENE_30),//3
true, //3
IndexWriter.MaxFieldLength.UNLIMITED); //3
}
public void close() throws IOException {
writer.close(); //4
}
public int index(String dataDir, FileFilter filter)
throws Exception {
File[] files = new File(dataDir).listFiles();
for (File f: files) {
if (!f.isDirectory() &&
!f.isHidden() &&
f.exists() &&
f.canRead() &&
(filter == null || filter.accept(f))) {
indexFile(f);
}
}
return writer.numDocs(); //5
}
private static class TextFilesFilter implements FileFilter {
public boolean accept(File path) {
return path.getName().toLowerCase() //6
.endsWith(".txt"); //6
}
}
protected Document getDocument(File f) throws Exception {
Document doc = new Document();
doc.add(new Field("contents", new FileReader(f))); //7
doc.add(new Field("filename", f.getName(), //8
Field.Store.YES, Field.Index.NOT_ANALYZED));//8
doc.add(new Field("fullpath", f.getCanonicalPath(), //9
Field.Store.YES, Field.Index.NOT_ANALYZED));//9
return doc;
}
private void indexFile(File f) throws Exception {
System.out.println("Indexing " + f.getCanonicalPath());
Document doc = getDocument(f);
writer.addDocument(doc); //10
}
}
/*
#1 Create index in this directory
#2 Index *.txt files from this directory
#3 Create Lucene IndexWriter
#4 Close IndexWriter
#5 Return number of documents indexed
#6 Index .txt files only, using FileFilter
#7 Index file content
#8 Index file name
#9 Index file full path
#10 Add document to Lucene index
*/
运行成功:
Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\apache1.0.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\apache1.1.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\apache2.0.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\cpl1.0.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\epl1.0.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\freebsd.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\gpl1.0.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\gpl2.0.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\gpl3.0.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\lgpl2.1.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\lgpl3.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\lpgl2.0.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\mit.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\mozilla1.1.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\mozilla_eula_firefox3.txt Indexing D:\JavaProjects\lia2e\src\lia\meetlucene\data\mozilla_eula_thunderbird2.txt Indexing 16 files took 369 milliseconds Process finished with exit code 0
你好!
在添加了您说的两个参数后,会报错,不知道是什么原因
Exception in thread “main” java.lang.NullPointerException
at lia.meetlucene.Indexer.index(Indexer.java:85)
at lia.meetlucene.Indexer.main(Indexer.java:55)
应该是我的参数的路径不对 我在run configuration–Argument中,将第二个参数args[1]的路径设置为Project Explorer中lia.meetlucene.data的路径,就运行成功了。跟着大牛的脚步亦步亦趋。
一直想买这本书来着,可是书太多也没时间看~