这是分类算法在欺诈检测方面的应用。
5.4.1交易数据中关于欺诈检测的一个用例
假设有如下样例数据:
正常交易集合:data/ch05/fraud/descriptions.txt
AMAZON.COM
USAIRWAY
EXPEDIA TRAVEL
欺诈交易集合:data/ch05/fraud/fraud-descriptions.txt
CAFE QWERTY
whole flash
food ASDFG
以及利用这些集合生成的训练数据集:
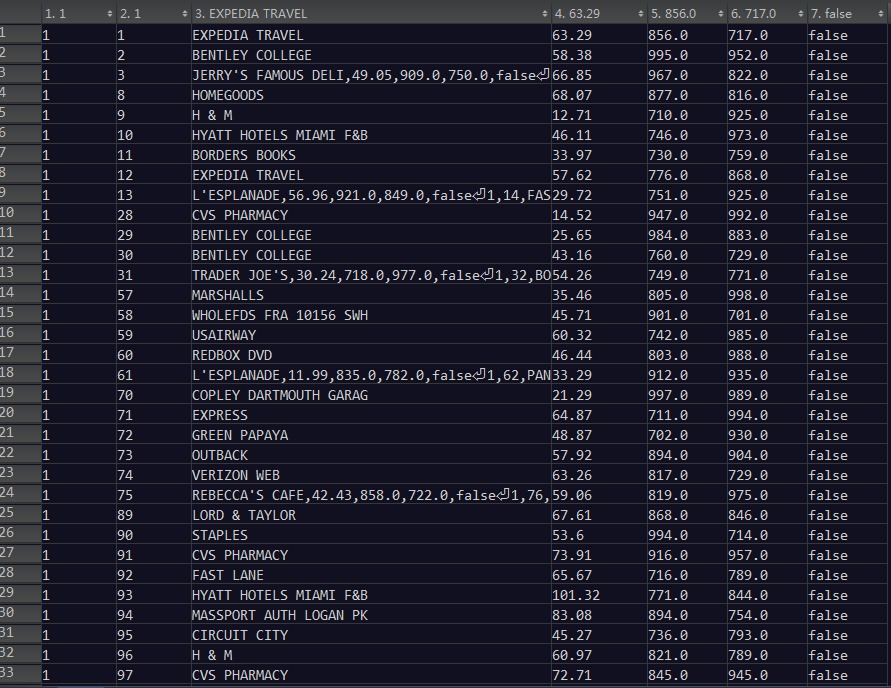
每条交易由如 下的属性值所确定(按序罗列):
•用户ID
•交易ID。
•交易的描述。
•交易总额。
•交易的GPS坐标。
•交易的坐标。
•—个用于确定交易是(true)否(false)属于欺诈的二值变量。
目标是创建一个分类器,基于上面的数据学习如何辨识一个欺诈交易。
5.4.2神经网络概览
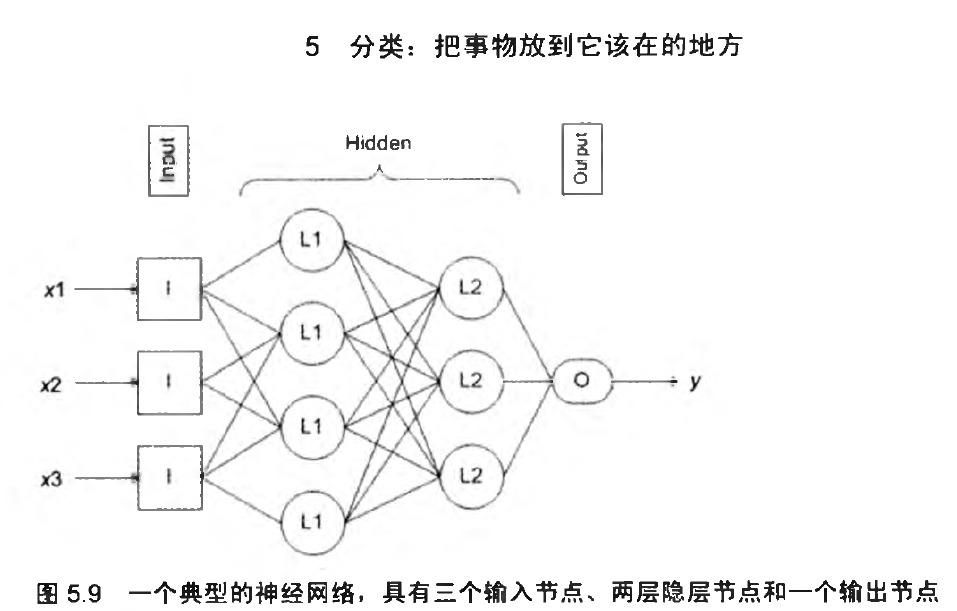
由具备IO的神经节点和其他神经节点构成。
5.4.3 —个可用的神经网络欺诈检测器
还是三步骤:训练、检验、生产:
package com.hankcs;
import iweb2.ch5.usecase.fraud.NNFraudClassifier;
import iweb2.ch5.usecase.fraud.data.TransactionDataset;
import iweb2.ch5.usecase.fraud.data.TransactionLoader;
import iweb2.ch5.usecase.fraud.util.FraudErrorEstimator;
public class ch5_3_FraudNN
{
public static void main(String[] args) throws Exception
{
// 载入训练集
TransactionDataset ds = TransactionLoader.loadTrainingDataset();
// 收集每个用户的消费习惯
ds.calculateUserStats();
//
//CREATE the classifier
//
// 分类器的实现,是对神经网络模型的包装
NNFraudClassifier nnFraudClassifier = new NNFraudClassifier(ds);
// Give it a name.
// It will be used later when we serialize the classifier
nnFraudClassifier.setName("MyNeuralClassifier");
//
//TRAIN the classifier
//
// Configure classifier with attributes that will be used as inputs into NN
// 使用交易属性:总额、位置与描述
nnFraudClassifier.useDefaultAttributes();
// Set the number of training iterations
// 数据会在网络中传播多少次
nnFraudClassifier.setNTrainingIterations(10);
// Start the training ...
nnFraudClassifier.train();
//
// STORE the classifier
//
// 序列化防宕机
nnFraudClassifier.save();
// You can load a previously saved classifier
// 载入一个己训练好的分类器
NNFraudClassifier nnClone = NNFraudClassifier.load(nnFraudClassifier.getName());
// Classify a couple of samples from Training set
// This should be a legitimate transaction
// 准备好要对两个交易进行分类,第一个ID (1)是合法交易
nnClone.classify("1");
// This should be a fraudulent transaction
// 第二个ID (305)属于欺诈交易。这只是一个检查性的测试
nnClone.classify("305");
// Now, calculate error rate for test set
// 创建了一个新的数据集
TransactionDataset testDS = TransactionLoader.loadTestDataset();
// 辅助类,它帮助我们评估分类器的精确度
FraudErrorEstimator auditor = new FraudErrorEstimator(testDS, nnClone);
auditor.run();
}
}
ds.calculateUserStats()里每个用户的消费习惯包含合法交易的最大金额和最小金额;合法交易描述中的单词集合;交易位置范围和中心点:
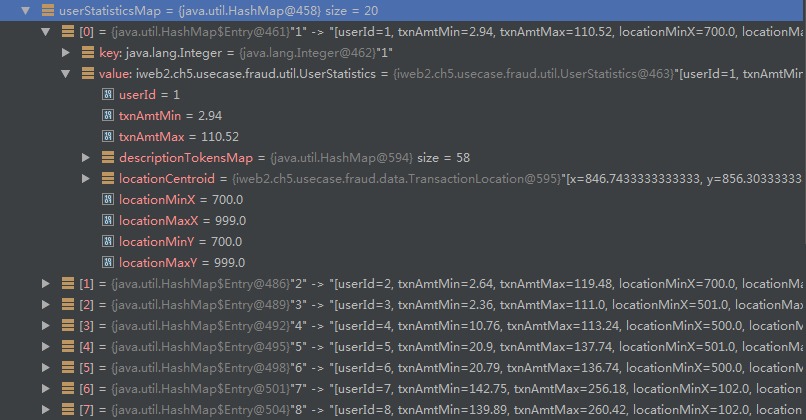
输出:
saved classifier in file: C:\iWeb2\data\ch05\MyNeuralClassifier loaded classifier from file: MyNeuralClassifier Transaction: >> 1:1:EXPEDIA TRAVEL:63.29:856.0:717.0:false Assessment: >> This is a VALID_TXN Transaction: >> 1:305:CANADIAN PHARMACY:3978.57:52.0:70.0:true Assessment: >> This is a FRAUD_TXN Total test dataset txns: 1100, Number of fraud txns:100 Classified correctly: 1100, Misclassified valid txns: 0, Misclassified fraud txns: 0
看起来失误率是0,但假如我们将data/ch05/fraud/test-txns.txt里面的“BLACK DIAMOND COFFEE”换成“TAOBAO”的话,就会发现有失误了:
saved classifier in file: C:\iWeb2\data\ch05\MyNeuralClassifier loaded classifier from file: MyNeuralClassifier Transaction: >> 1:1:EXPEDIA TRAVEL:63.29:856.0:717.0:false Assessment: >> This is a VALID_TXN Transaction: >> 1:305:CANADIAN PHARMACY:3978.57:52.0:70.0:true Assessment: >> This is a FRAUD_TXN - n_txnamt = 0.33646216373137205 - n_location = 0.6601082057290067 - n_description = 0.0 - userid = 25.0 - txnid = 500523 - txnamt = 63.79 - location_x = 533.0 - location_y = 503.0 - description = TAOBAO --> VALID_TXN - n_txnamt = 1.0138677641585399 - n_location = 0.5745841533228392 - n_description = 0.0 - userid = 26.0 - txnid = 500574 - txnamt = 127.97 - location_x = 734.0 - location_y = 507.0 - description = TAOBAO --> VALID_TXN - n_txnamt = 0.35626185958254264 - n_location = 0.658153849503683 - n_description = 0.0 - userid = 23.0 - txnid = 500273 - txnamt = 47.76 - location_x = 966.0 - location_y = 991.0 - description = TAOBAO --> VALID_TXN - n_txnamt = 0.48453914767096135 - n_location = 0.655796929157372 - n_description = 0.0 - userid = 21.0 - txnid = 500025 - txnamt = 50.47 - location_x = 980.0 - location_y = 996.0 - description = TAOBAO --> VALID_TXN Total test dataset txns: 1100, Number of fraud txns:100 Classified correctly: 1096, Misclassified valid txns: 4, Misclassified fraud txns: 0
这是因为第一次用的测试数据跟训练集数据的属性值是相同,而第二次的TAOBAO对于分类器来说是个陌生的描述。这39个TAOBAO交易中有4个被冤枉了。
5.4.4神经网络欺诈检测器剖析
最重要的一步是训练神经网络:
/**
* 训练神经网络
* @param nIterations 实例在神经网络中传播的次数
*/
private void trainNeuralNetwork(int nIterations)
{
for (int i = 1; i <= nIterations; i++)
{
for (Instance instance : ts.getInstances().values())
{
double[] nnInput = createNNInputs(instance);
double[] nnExpectedOutput = createNNOutputs(instance);
nn.train(nnInput, nnExpectedOutput);
}
if (verbose)
{
System.out.println("finished training pass: " + i + " out of " + nIterations);
}
}
}
nn指的是TransactionNN,也就是—个特别的用于欺诈检测案例的神经网络:
public TransactionNN(String name)
{
super(name);
createNN351();
}
这个神经网络的规模是351:
/**
* 三个输入节点、五个隐层节点与一个输出层节点
*/
private void createNN351()
{
// 1. Define Layers, Nodes and Node Biases
Layer inputLayer = createInputLayer(
0, // layer id
3 // number of nodes
);
Layer hiddenLayer = createHiddenLayer(
1, // layer id
5, // number of nodes
new double[]{1, 1.5, 1, 0.5, 1} // node biases
// 节点额外权值
);
Layer outputLayer = createOutputLayer(
2, // layer id
1, // number of nodes
new double[]{1.5} // node biases
);
setInputLayer(inputLayer);
setOutputLayer(outputLayer);
addHiddenLayer(hiddenLayer);
// 2. Define links and weights between nodes
// Id format: <layerId:nodeIdwithinLayer>
// Weights for links from Input Layer to Hidden Layer
// 我们逐个为节点间建立连接(突触)
setLink("0:0", "1:0", 0.25);
setLink("0:0", "1:1", -0.5);
setLink("0:0", "1:2", 0.25);
setLink("0:0", "1:3", 0.25);
setLink("0:0", "1:4", -0.5);
setLink("0:1", "1:0", 0.25);
setLink("0:1", "1:1", -0.5);
setLink("0:1", "1:2", 0.25);
setLink("0:1", "1:3", 0.25);
setLink("0:1", "1:4", -0.5);
setLink("0:2", "1:0", 0.25);
setLink("0:2", "1:1", -0.5);
setLink("0:2", "1:2", 0.25);
setLink("0:2", "1:3", 0.25);
setLink("0:2", "1:4", -0.5);
// Weights for links from Hidden Layer to Output Layer
setLink("1:0", "2:0", -0.5);
setLink("1:1", "2:0", 0.5);
setLink("1:2", "2:0", -0.5);
setLink("1:3", "2:0", -0.5);
setLink("1:4", "2:0", 0.5);
if (isVerbose())
{
System.out.println("NN created");
}
}
对于351的规模,3指的是交易金额的标准化、交易描述的雅克比系数、用户交易中心点和当前交易点的距离这三个输入。
其中setLink()是很重要的方法:
/** * 建立突触链接 * @param fromNodeId 起点 * @param toNodeId 重点 * @param w 权值 */ public void setLink(String fromNodeId, String toNodeId, double w)
5.4.5创建通用神经网络的基类
也就是TransactionNN的基类、神经网络的通用实现——BaseNN类。
BaseNN (结构层面):通用神经网络基类代码摘录
/**
* 为网络创建输入层,它以层的ID和节点数量作为参数,实例化一个BaseLayer对象
* @param layerId
* @param nNodes
* @return
*/
public Layer createInputLayer(int layerId, int nNodes)
{
BaseLayer baseLayer = new BaseLayer(layerId);
for (int i = 0; i < nNodes; i++)
{
// 节点
Node node = createInputNode(layerId + ":" + i);
// 突触(入链)
Link inlink = new BaseLink();
inlink.setFromNode(node);
// 初始权重为1,训练过程中保持不变
inlink.setWeight(1.0);
node.addInlink(inlink);
baseLayer.addNode(node);
}
return baseLayer;
}
/**
* 为网络创建隐层,它以层的ID、节点数量以及这些节点的偏移值作为参数
* @param layerId
* @param nNodes
* @param bias
* @return
*/
public Layer createHiddenLayer(int layerId, int nNodes, double[] bias)
{
if (bias.length != nNodes)
{
throw new RuntimeException("Each node should have bias defined.");
}
BaseLayer baseLayer = new BaseLayer(layerId);
for (int i = 0; i < nNodes; i++)
{
Node node = createHiddenNode(layerId + ":" + i);
node.setBias(bias[i]);
baseLayer.addNode(node);
}
return baseLayer;
}
/**
* 构造输出层
* @param layerId
* @param nNodes
* @param bias
* @return
*/
public Layer createOutputLayer(int layerId, int nNodes, double[] bias)
{
if (bias.length != nNodes)
{
throw new RuntimeException("Each node should have bias defined.");
}
BaseLayer baseLayer = new BaseLayer(layerId);
for (int i = 0; i < nNodes; i++)
{
Node node = createOutputNode(layerId + ":" + i);
node.setBias(bias[i]);
baseLayer.addNode(node);
}
return baseLayer;
}
BaseNN (操作层面):通用神经网络基类代码摘录:
/**
* 训练
* @param tX 输入节点
* @param tY 输出节点
*/
public void train(double[] tX, double[] tY)
{
double lastError = 0.0;
int i = 0;
while (true) // 提升分类器的精度
{
i++;
// Evaluate sample
double[] y = classify(tX);
double err = error(tY, y);
if (Double.isInfinite(err) || Double.isNaN(err))
{
// Couldn't even evaluate the error. Stop.
// 如果无法计算误差,跳出
throw new RuntimeException(
"Training failed. Couldn't evaluate the error: " + err +
". Try some other NN configuration, parameters.");
}
double convergence = Math.abs(err - lastError);
if (err <= ERROR_THRESHOLD)
{
// Good enough. No need to adjust weights for this sample.
// 误差小于阀值,够好了,跳出
lastError = err;
if (verbose)
{
System.out.print("Error Threshold: " + ERROR_THRESHOLD);
System.out.print(" | Error Achieved: " + err);
System.out.print(" | Number of Iterations: " + i);
System.out.println(" | Absolute convergence: " + convergence);
}
break;
}
if (convergence <= CONVERGENCE_THRESHOLD)
{ // If we made almost no progress stop.
// No change. Stop.
// 误差收敛速度不明显,跳出
if (verbose)
{
System.out.print("Error Threshold: " + ERROR_THRESHOLD);
System.out.print(" | Error Achieved: " + err);
System.out.print(" | Number of Iterations: " + i);
System.out.println(" | Absolute convergence: " + convergence);
}
break;
}
lastError = err;
// Set expected values so that we can determine the error
// 把输出节点的值设为期望值
outputLayer.setExpectedOutputValues(tY);
/*
* Calculate weight adjustments in the whole network
*/
// 调整输出节点的权重
outputLayer.calculateWeightAdjustments();
for (Layer hLayer : hiddenLayers)
{
// layer order doesn't matter because we will update weights later
// 调整中间层的权重
hLayer.calculateWeightAdjustments(); // WeightIncrements
}
/*
* Update Weights
*/
outputLayer.updateWeights();
for (Layer hLayer : hiddenLayers)
{
// layer order doesn't matter.
hLayer.updateWeights();
}
}
//System.out.println("i = " + i + ", err = " + lastError);
}
神经网络不断地计算输出——对比误差——调整突触的权重——计算输出——对比误差……直到误差够小了或者误差降不下来了就终止。关于神经网络算法的基础《智能Web算法》没有深入,我也没有这方面的需求,所以就这样吧。《智能Web算法》终究是一本普及性质的书,学术性的东西还是得看论文吧。