聚类指的是分组时,将类似的事物放在一起。应用于发布有针对性的广告,显示相关文章和在网站中构建社交网络等方面。
4.1.1 网站中的用户组:案例研究
在一个类似SourceForge.net的网站中,可以用于聚类分析的用户数据有:年龄、收入、教育、技能、社交、有偿与否。接下来的两节会尽可能地根据这些属性值对用户分组。
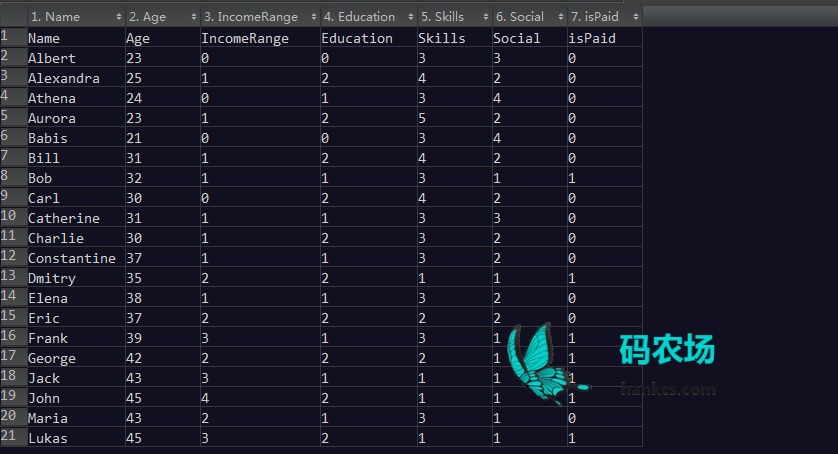
4.1.2 用SQL order by 字句分组
Order by A,B 的语句中A的优先级>B的优先级,如果有很多个属性的话不够灵活。
4.1.3 用数组排序分组
最直观的解决方法是用Java代码直接操控数组元素的排序比较:
package com.hankcs;
import iweb2.ch4.clustering.SortedArrayClustering;
import iweb2.ch4.data.SFData;
import iweb2.ch4.data.SFDataset;
public class ch4_1_SortedArrayClustering
{
public static void main(String[] args) throws Exception
{
SFDataset ds = SFData.createDataset();
SortedArrayClustering.cluster(ds.getData());
}
}
输出
From file: C:/iWeb2/data/ch04/clusteringSF.dat Using attribute names: [Age, IncomeRange, Education, Skills, Social, isPaid] Loaded 20 data points. John([45.0, 4.0, 2.0, 1.0, 1.0, 1.0]) Lukas([45.0, 3.0, 2.0, 1.0, 1.0, 1.0]) Maria([43.0, 2.0, 1.0, 3.0, 1.0, 0.0]) Jack([43.0, 3.0, 1.0, 1.0, 1.0, 1.0]) George([42.0, 2.0, 2.0, 2.0, 1.0, 1.0]) Frank([39.0, 3.0, 1.0, 3.0, 1.0, 1.0]) Elena([38.0, 1.0, 1.0, 3.0, 2.0, 0.0]) Eric([37.0, 2.0, 2.0, 2.0, 2.0, 0.0]) Constantine([37.0, 1.0, 1.0, 3.0, 2.0, 0.0]) Dmitry([35.0, 2.0, 2.0, 1.0, 1.0, 1.0]) Bob([32.0, 1.0, 1.0, 3.0, 1.0, 1.0]) Bill([31.0, 1.0, 2.0, 4.0, 2.0, 0.0]) Catherine([31.0, 1.0, 1.0, 3.0, 3.0, 0.0]) Carl([30.0, 0.0, 2.0, 4.0, 2.0, 0.0]) Charlie([30.0, 1.0, 2.0, 3.0, 2.0, 0.0]) Alexandra([25.0, 1.0, 2.0, 4.0, 2.0, 0.0]) Athena([24.0, 0.0, 1.0, 3.0, 4.0, 0.0]) Aurora([23.0, 1.0, 2.0, 5.0, 2.0, 0.0]) Albert([23.0, 0.0, 0.0, 3.0, 3.0, 0.0]) Babis([21.0, 0.0, 0.0, 3.0, 4.0, 0.0])
这个排序算法十分简单粗暴,通过将每个用户的数据作为一个向量,计算该向量到原点的距离,以此作为排序依据。
public class SortedArrayClustering
{
public static void cluster(DataPoint[] points)
{
Arrays.sort(points, new Comparator<DataPoint>()
{
public int compare(DataPoint p1, DataPoint p2)
{ // 按降序排列
int result = 0;
// sort based on score value
// 根据分值排序
if (p1.getR() < p2.getR())
{
result = 1; // sorting in descending order
}
else if (p1.getR() > p2.getR())
{
result = -1;
}
else
{
result = 0;
}
return result;
}
});
for (int i = 0; i < points.length; i++)
{
System.out.println(points[i].toShortString());
}
}
}
getR是计算向量到原点的距离:
/**
* 获取向量到原点的距离
* @return
*/
public double getR()
{
EuclideanDistance euclid = new EuclideanDistance();
int n = attributes.length;
double[] x = new double[n];
for (int i = 0; i < n; i++)
{
x[i] = 0d;
}
return euclid.getDistance(x, this.numericAttributeValues);
}
EuclideanDistance是用来计算欧几里得距离的类:
package iweb2.ch4.similarity;
/**
* 欧几里得距离计算类
*/
public class EuclideanDistance implements Distance
{
public EuclideanDistance()
{
// empty
}
/**
* 计算x向量与y向量的欧几里得距离
* @param x
* @param y
* @return
*/
public double getDistance(double[] x, double[] y)
{
double sumXY2 = 0.0;
for (int i = 0, n = x.length; i < n; i++)
{
sumXY2 += Math.pow(x[i] - y[i], 2);
}
return Math.sqrt(sumXY2);
}
public double getDistance(Double[] x, Double[] y)
{
double sumXY2 = 0.0;
for (int i = 0, n = x.length; i < n; i++)
{
sumXY2 += Math.pow(x[i] - y[i], 2);
}
return Math.sqrt(sumXY2);
}
}
这个算法有两个问题:
1、群组界限不明
2、年龄对排序影响太大