
这是《智能Web算法》的笔记,备忘备查。
Lucene是一个成功的开源IR(信息获取)库,可以快速地分析、索引和搜索文档(网页和电子文档)。
Lucene现在最新版本已经有4.6了,由于《智能Web算法》的配书代码用的是2.3.0,所以我依然使用2.3.0,只不过用源码替换掉了jar,这样能够更加接近核心。
这一节的完整BeanShell脚本被我写成了class,方便调试:
package com.hankcs;
import iweb2.ch2.shell.FetchAndProcessCrawler;
import iweb2.ch2.shell.LuceneIndexer;
import iweb2.ch2.shell.MySearcher;
/**
* @author hankcs
*/
public class ch2_1_LuceneSearch
{
public static void main(String[] args)
{
// ------------------------------------------------------
// Collecting data and searching with Lucene
// ------------------------------------------------------
//
// -- Data (default URL list)
//
// 创建一个抓取爬行处理者
FetchAndProcessCrawler crawler = new FetchAndProcessCrawler("C:/iWeb2/data/ch02",5,200);
// 设置默认的链接,也就是c:/iWeb2/data/ch02/下的全部html文件
crawler.setDefaultUrls();
// 添加垃圾网页
// crawler.addUrl("file:///c:/iWeb2/data/ch02/spam-01.html");
crawler.run();
//
// -- Lucene
//
LuceneIndexer luceneIndexer = new LuceneIndexer(crawler.getRootDir());
luceneIndexer.run();
MySearcher oracle = new MySearcher(luceneIndexer.getLuceneDir());
oracle.search("armstrong",5);
}
}
我画了个图:
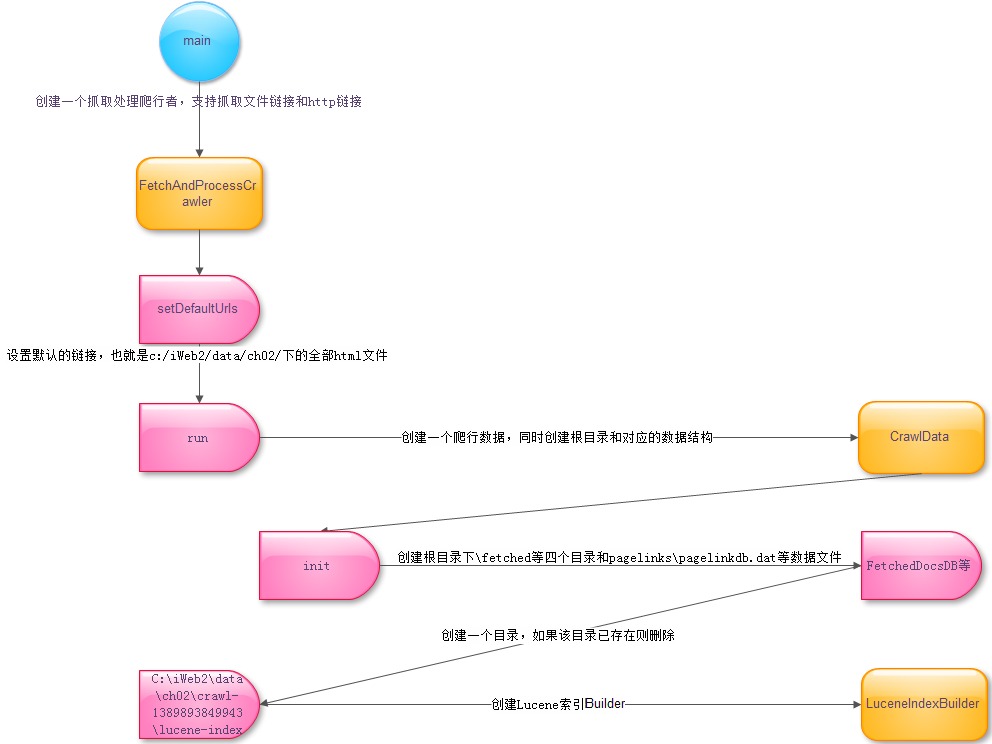
搜索引擎的第一部工作是采集,需要创建一个爬行者:
/**
* 创建一个抓取处理爬行者,支持抓取文件链接和http链接
* @param dir 路径,比如C:/iWeb2/data/ch02
* @param maxDepth 最大深度,比如5
* @param maxDocs 最大文档数
*/
public FetchAndProcessCrawler(String dir, int maxDepth, int maxDocs) {
rootDir = dir;
// 检验参数是否有效
if ( rootDir == null || rootDir.trim().length() == 0) {
String prefix = System.getProperty("iweb2.home");
if (prefix == null) {
prefix = "..";
}
rootDir = System.getProperty("iweb2.home")+System.getProperty("file.separator")+"data";
}
// 生成本次的根目录 比如 C:/iWeb2/data/ch02\crawl-1389795965623
rootDir = rootDir+System.getProperty("file.separator")+"crawl-" + System.currentTimeMillis();
this.maxDepth = maxDepth;
this.maxDocs = maxDocs;
this.seedUrls = new ArrayList<String>();
/* default url filter configuration */
this.urlFilter = new URLFilter();
urlFilter.setAllowFileUrls(true);
urlFilter.setAllowHttpUrls(true);
}
然后运行抓取作业:
/**
* 开始抓取
*/
public void run() {
crawlData = new CrawlData(rootDir);
BasicWebCrawler webCrawler = new BasicWebCrawler(crawlData);
webCrawler.addSeedUrls(getSeedUrls());
webCrawler.setURLFilter(urlFilter);
long t0 = System.currentTimeMillis();
/* run crawl */
webCrawler.fetchAndProcess(maxDepth, maxDocs);
System.out.println("Timer (s): [Crawler processed data] --> " +
(System.currentTimeMillis()-t0)*0.001);
}
其中fetchAndProcess使用了代理的设计模式,可以根据协议的不同处理文件和http两种页面:
/**
* 抓取文件或页面
* @param urls
* @param fetchedDocsDB
* @param groupId
*/
private void fetchPages(List<String> urls, FetchedDocsDB fetchedDocsDB, String groupId) {
DocumentIdUtils docIdUtils = new DocumentIdUtils();
int docSequenceInGroup = 1;
List<UrlGroup> urlGroups = UrlUtils.groupByProtocolAndHost(urls);
for( UrlGroup urlGroup : urlGroups ) {
// 通过文件类型返回不同的代理
// 有http抓取代理和file抓取代理两种
Transport t = getTransport(urlGroup.getProtocol());
try {
t.init();
for(String url : urlGroup.getUrls() ) {
try {
FetchedDocument doc = t.fetch(url);
String documentId = docIdUtils.getDocumentId(groupId, docSequenceInGroup);
doc.setDocumentId(documentId);
fetchedDocsDB.saveDocument(doc);
if( t.pauseRequired() ) {
pause();
}
}
catch(Exception e) {
System.out.println("Failed to fetch document from url: '" + url + "'.\n"+
e.getMessage());
crawlData.getKnownUrlsDB().updateUrlStatus(
url, KnownUrlEntry.STATUS_PROCESSED_ERROR);
}
docSequenceInGroup++;
}
}
finally {
t.clear();
}
}
}
抓取并且解析和分析的结果存放在工作目录下,这是原始的未索引的数据

然后索引它们,数据的输入借助ProcessedDocsDB,数据的索引并输出借助IndexWriter
org.apache.lucene.index.IndexWriter public void addDocument(Document doc) throws CorruptIndexException, IOException
下图高亮的是索引存放目录:

索引完毕即可使用MySearcher搜索:
iweb2.ch2.shell.MySearcher public SearchResult[] search(String query, int numberOfMatches)
public SearchResult[] search(String query, int numberOfMatches)
{
SearchResult[] docResults = new SearchResult[0];
// Lucene索引搜索器
IndexSearcher is = null;
try
{
// C:/iWeb2/data/ch02\crawl-1390578798123\lucene-index
// 打开Lucene索引
is = new IndexSearcher(FSDirectory.getDirectory(indexDir));
} catch (IOException ioX)
{
System.out.println("ERROR: " + ioX.getMessage());
}
// 创建查询解析器
QueryParser qp = new QueryParser(
"content", // 要查询的域
new StandardAnalyzer() // 分词器,默认是英文分词器,使用空格分词
// 因为是英文,就算用new WhitespaceAnalyzer()也是一样的结果
);
Query q = null;
try
{
// 将文本查询转换为Lucene查询
q = qp.parse(query);
} catch (ParseException pX)
{
System.out.println("ERROR: " + pX.getMessage());
}
// 搜索结果,其实是一个排名表
Hits hits = null;
try
{
hits = is.search(q);
// 限制最大结果数
int n = Math.min(hits.length(), numberOfMatches);
docResults = new SearchResult[n];
for (int i = 0; i < n; i++)
{
docResults[i] = new SearchResult(hits.doc(i).get("docid"),
hits.doc(i).get("doctype"),
hits.doc(i).get("title"),
hits.doc(i).get("url"),
hits.score(i));
}
is.close();
} catch (IOException ioX)
{
System.out.println("ERROR: " + ioX.getMessage());
}
String header = "Search results using Lucene index scores:";
boolean showTitle = true;
printResults(header, "Query: " + query, docResults, showTitle);
return docResults;
}
大神,我照着你的代码运行了下,报错啊(如下)![[可怜]](http://img.t.sinajs.cn/t35/style/images/common/face/ext/normal/af/kl_org.gif "[可怜]")
ERROR:
Failed to load properties from resource: ‘/iweb2.properties’.
null
是不是要把iweb2.properties这个文件放在根目录下,我试了还是不行。给支个招吧
扔到iWeb2src就行了