原书译为“鲁棒的链接型聚类”,这个“鲁棒”真的太绅(henn)士(tai)了。我查了下,“鲁棒”来源于英文“Robust”,意为“强健的,稳固的,耐用的,粗野的,浓的”等。“Robustness”的一般含义是“强度, 坚固性”。我还是接受维基百科的翻译,译作“健壮”的比较好。
与前两种聚类算法不同,这个算法适用于类别型数据,比如关键字、布尔值和枚举值等,另外,它还能很好地处理大型数据集。
这一节的测试数据:
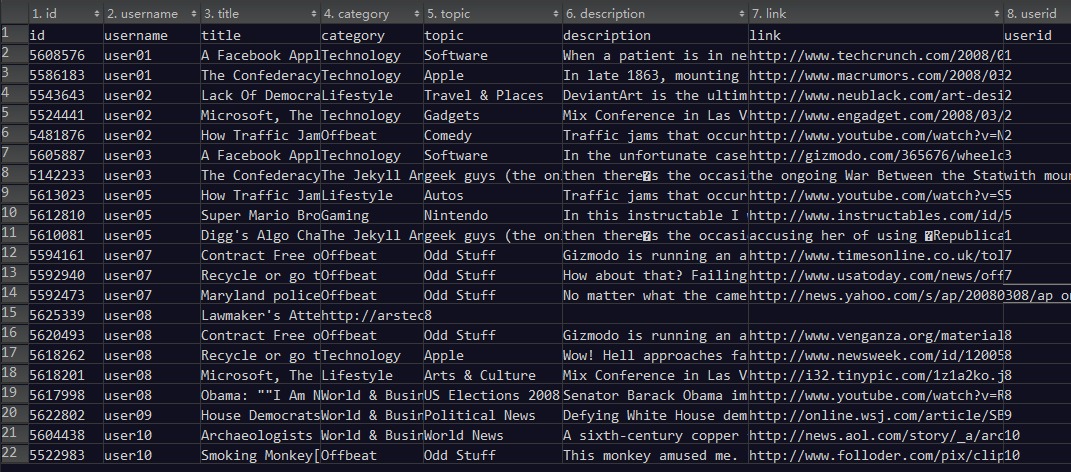
4.5.1 ROCK简介
主程序:
package com.hankcs;
import iweb2.ch4.clustering.hierarchical.Dendrogram;
import iweb2.ch4.clustering.rock.ROCKAlgorithm;
import iweb2.ch4.data.MyDiggSpaceData;
import iweb2.ch4.data.MyDiggSpaceDataset;
import iweb2.ch4.model.DataPoint;
public class ch4_4_Rock
{
public static void main(String[] args) throws Exception
{
// 加载Digg新闻,只是用前15条
MyDiggSpaceDataset ds = MyDiggSpaceData.createDataset(15);
DataPoint[] dps = ds.getData();
// 初始化ROCK,寻找5个聚类
ROCKAlgorithm rock = new ROCKAlgorithm(dps, 5, 0.2);
Dendrogram dnd = rock.cluster();
dnd.print(21);
}
}
输出:
From file: C:/iWeb2/data/ch04/ch4_digg_stories.csv
Loaded 10 users.
Loaded 48 stories (items).
Number of clusters: 23
Clusters for: level=21, Goodness=1.044451296741812
____________________________________________________________
{5619782:Lack Of Democracy on Digg and Wikipedia?,
5611165:Lack Of Democracy on Digg and Wikipedia?}
____________________________________________________________
____________________________________________________________
{5598008:The Confederacy's Special Agent,
5613383:The Confederacy's Special Agent,
5613380:The Confederacy's Special Agent,
5142233:The Confederacy's Special Agent,
5620839:The Confederacy's Special Agent,
5586183:The Confederacy's Special Agent,
5610584:The Confederacy's Special Agent}
____________________________________________________________
____________________________________________________________
{5571841:Lack Of Democracy on Digg and Wikipedia?,
5543643:Lack Of Democracy on Digg and Wikipedia?}
____________________________________________________________
____________________________________________________________
{5585930:Microsoft, The Jekyll And Hyde Of Companies,
5524441:Microsoft, The Jekyll And Hyde Of Companies,
5609070:Microsoft, The Jekyll And Hyde Of Companies,
5618201:Microsoft, The Jekyll And Hyde Of Companies,
5620878:Microsoft, The Jekyll And Hyde Of Companies,
5609797:Microsoft, The Jekyll And Hyde Of Companies}
____________________________________________________________
____________________________________________________________
{5608052:Contract Free on AT&T,
5620493:Contract Free on AT&T,
5621623:Contract Free on AT&T,
4955184:Contract Free on AT&T,
5594161:Contract Free on AT&T}
____________________________________________________________
____________________________________________________________
{5607788:Recycle or go to Hell, warns Vatican -- part I,
5592940:Recycle or go to Hell, warns Vatican -- part II,
5618262:Recycle or go to Hell, warns Vatican -- part III,
5595841:Recycle or go to Hell, warns Vatican --- part IV}
____________________________________________________________
可见聚类是成功的,类似part I等等的相似文章被归入同一类。
4.5.2 为什么ROCK这么强大?
ROCK的核心思想是利用链接作为相似性的度量,而不是仅仅依赖于距离。
package iweb2.ch4.clustering.rock;
import iweb2.ch4.clustering.hierarchical.Dendrogram;
import iweb2.ch4.model.Cluster;
import iweb2.ch4.model.DataPoint;
import iweb2.ch4.similarity.JaccardCoefficient;
import iweb2.ch4.similarity.SimilarityMeasure;
import java.util.ArrayList;
import java.util.List;
public class ROCKAlgorithm
{
private DataPoint[] points;
private int k;
private double th;
/**
* 相似度矩阵
*/
private SimilarityMeasure similarityMeasure;
/**
* 链接矩阵
*/
private LinkMatrix linkMatrix;
/**
*
* @param points 要聚类的数据点
* @param k 聚类的最小数量
* @param th 创建链接的阀值
*/
public ROCKAlgorithm(DataPoint[] points, int k, double th)
{
this.points = points;
this.k = k;
this.th = th;
this.similarityMeasure = new JaccardCoefficient();
//this.similarityMeasure = new CosineSimilarity();
this.linkMatrix = new LinkMatrix(points, similarityMeasure, th);
}
/**
* 聚类
* @return 树状图
*/
public Dendrogram cluster()
{
// Create a new cluster out of every point.
// 初始化,为每个数据点创建一个新的聚类
List<Cluster> initialClusters = new ArrayList<Cluster>();
for (int i = 0, n = points.length; i < n; i++)
{
Cluster cluster = new Cluster(points[i]);
initialClusters.add(cluster);
}
double g = Double.POSITIVE_INFINITY;
Dendrogram dnd = new Dendrogram("Goodness");
dnd.addLevel(String.valueOf(g), initialClusters);
// 创建一个度量值,判断两个聚类是否应该合并,度量值越大就越应该合并
MergeGoodnessMeasure goodnessMeasure = new MergeGoodnessMeasure(th);
// 封装了所有根据度量值识别最佳聚类所需的数据和算法
ROCKClusters allClusters = new ROCKClusters(initialClusters,
linkMatrix,
goodnessMeasure);
int nClusters = allClusters.size();
while (nClusters > k) // 如果聚类数量等于所需的数量则终止
{
int nClustersBeforeMerge = nClusters;
g = allClusters.mergeBestCandidates();
nClusters = allClusters.size();
if (nClusters == nClustersBeforeMerge)
{
// there are no linked clusters to merge
// 前后两次迭代中聚类的数量没有变化,终止
break;
}
dnd.addLevel(String.valueOf(g), allClusters.getAllClusters());
}
System.out.println("Number of clusters: " + allClusters.getAllClusters().size());
return dnd;
}
public static void main(String[] args)
{
//Define data
DataPoint[] elements = new DataPoint[4];
elements[0] = new DataPoint("Doc1", new String[]{"book"});
elements[1] = new DataPoint("Doc2", new String[]{"water", "sun", "sand", "swim"});
elements[2] = new DataPoint("Doc3", new String[]{"water", "sun", "swim", "read"});
elements[3] = new DataPoint("Doc4", new String[]{"read", "sand"});
int k = 1;
double th = 0.2;
ROCKAlgorithm rock = new ROCKAlgorithm(elements, k, th);
Dendrogram dnd = rock.cluster();
dnd.printAll();
}
public int getK()
{
return k;
}
public double getTh()
{
return th;
}
public SimilarityMeasure getSimilarityMeasure()
{
return similarityMeasure;
}
public LinkMatrix getLinkMatrix()
{
return linkMatrix;
}
}
MergeGoodnessMeasure封装了评判聚类优劣的依据,它要防止的前车之鉴是“连锁效应”(两个很近的点导致两个聚类合并)。为了实现这个目标,ROCK算法使用了链接。链接指的是,两个点具有共同邻居则它们之间有链接。MergeGoodnessMeasure评判是否应当聚类的依据是,两个聚类中数据点之间的链接数量,具体说来,聚合的好坏程度,等于X、Y之间的链接数量 / X、Y期望的链接数量的积。为何使用这么复杂的公式的原因是,要消除“某个别的点之间的链接数量很大导致XY之间链接数量很大”的连锁效应。
package iweb2.ch4.clustering.rock;
/**
* Goodness measure for merging two clusters.
* 评判最优聚类的依据
*/
public class MergeGoodnessMeasure
{
/**
* Threshold value that was used to identify neighbors among points.
* 识别邻居的阀值
*/
private double linkThreshold;
/**
* Intermediate value that is used in calculation of goodness measure
* and stays the same for different clusters.
* 在最优聚类计算过程中保持不变的中间值
*/
private double p;
public MergeGoodnessMeasure(double th)
{
this.linkThreshold = th;
this.p = 1.0 + 2.0 * f(th);
}
/**
*
* @param nLinks 聚类X、Y之间的链接数量
* @param nX X中数据点的数量
* @param nY Y中数据点的数量
* @return 聚合的好坏程度,等于X、Y之间的链接数量 / X、Y期望的链接数量的积
*/
public double g(int nLinks, int nX, int nY)
{
double a = Math.pow(nX + nY, p);
// 估计X和Y中的链接总数
double b = Math.pow(nX, p);
double c = Math.pow(nY, p);
return nLinks / (a - b - c);
}
/**
* 计算中间值
* @param th 阀值
* @return 中间值
*/
private double f(double th)
{
/*
* This implementation assumes that linkThreshold was a threshold for
* similarity measure (as opposed to dissimilarity/distance).
*/
return (1.0 - th) / (1.0 + th);
}
/**
* @return the linkThreshold
*/
public double getTh()
{
return linkThreshold;
}
public void setTh(double th)
{
this.linkThreshold = th;
}
}
ROCKClusters 从所有度量值中找出最大值,并且合并它对应的两个聚类,ROCKAlgorithm不断重复这一操作直至聚类的数量满足要求。
数据点是什么意思