DBSCAN是一种基于密度的空间聚类算法,适用于含噪声的数据。
4.6.1 基于密度的算法简介
生活经验,将密度集中点圈起来就成为一个聚类,而那些分散的点,则被称为噪声。DBSCAN算法的目的是发现数据集中的聚类和噪声。
主程序:
package com.hankcs;
import iweb2.ch4.clustering.dbscan.DBSCANAlgorithm;
import iweb2.ch4.data.MyDiggSpaceData;
import iweb2.ch4.data.MyDiggSpaceDataset;
import iweb2.ch4.model.DataPoint;
import iweb2.ch4.similarity.CosineDistance;
public class ch4_4_DBSCAN
{
public static void main(String[] args) throws Exception
{
// 加载前15个Digg的新闻
MyDiggSpaceDataset ds = MyDiggSpaceData.createDataset(15);
DataPoint[] dps = ds.getData();
CosineDistance cosD = new CosineDistance();
// 初始化DBSCAN算法
DBSCANAlgorithm dbscan = new DBSCANAlgorithm(dps, cosD, 0.8, 2, true);
dbscan.cluster();
}
}
输出:
Clusters:
____________________________________________________________
1:
{5608576:A Facebook Application To Find Blood Donors Fast,
5611687:A Facebook Application To Find Blood Donors Fast,
5605887:A Facebook Application To Find Blood Donors Fast}
____________________________________________________________
____________________________________________________________
2:
{5598008:The Confederacy's Special Agent,
5142233:The Confederacy's Special Agent,
5613380:The Confederacy's Special Agent,
5610584:The Confederacy's Special Agent,
5613383:The Confederacy's Special Agent,
5620839:The Confederacy's Special Agent,
5586183:The Confederacy's Special Agent}
____________________________________________________________
____________________________________________________________
3:
{5620878:Microsoft, The Jekyll And Hyde Of Companies,
5618201:Microsoft, The Jekyll And Hyde Of Companies,
5585930:Microsoft, The Jekyll And Hyde Of Companies,
5609797:Microsoft, The Jekyll And Hyde Of Companies,
5609070:Microsoft, The Jekyll And Hyde Of Companies,
5524441:Microsoft, The Jekyll And Hyde Of Companies}
____________________________________________________________
____________________________________________________________
4:
{5594161:Contract Free on AT&T,
4955184:Contract Free on AT&T,
5608052:Contract Free on AT&T,
5621623:Contract Free on AT&T,
5579109:Contract Free on AT&T,
5620493:Contract Free on AT&T}
____________________________________________________________
____________________________________________________________
5:
{5607863:Lack Of Democracy on Digg and Wikipedia?,
5571841:Lack Of Democracy on Digg and Wikipedia?,
5619782:Lack Of Democracy on Digg and Wikipedia?,
5611165:Lack Of Democracy on Digg and Wikipedia?,
5543643:Lack Of Democracy on Digg and Wikipedia?}
____________________________________________________________
____________________________________________________________
6:
{5613023:How Traffic Jams Occur : Simulation,
5481876:How Traffic Jams Occur : Simulation}
____________________________________________________________
____________________________________________________________
7:
{5617459:Robotic drumstick keeps novices on the beat,
5619693:Robotic drumstick keeps novices on the beat}
____________________________________________________________
____________________________________________________________
8:
{5625315:Obama Accuses Clinton of Using ""Republican Tactics"",
5617998:Obama: ""I Am NOT Running for Vice President""}
____________________________________________________________
____________________________________________________________
9:
{5618262:Recycle or go to Hell, warns Vatican -- part III,
5592940:Recycle or go to Hell, warns Vatican -- part II,
5607788:Recycle or go to Hell, warns Vatican -- part I,
5595841:Recycle or go to Hell, warns Vatican --- part IV}
____________________________________________________________
Noise Elements:
{5619818:A Facebook Application To Find Blood Donors Fast,
5522983:Smoking Monkey[flash],
5612810:Super Mario Bros Inspired Wii with USB base [ Pics ],
5609833:NSA's Domestic Spying Grows As Agency Sweeps Up Data,
5592473:Maryland police officers refuse to pay speeding tickets,
5625339:Lawmaker's Attempt to Criminalize Anonymous Posting Doomed,
5610213:Senate panel critiques prewar claims by White House,
5610081:Digg's Algo Change Cut Promotions by 38%,
5604438:Archaeologists Unveil Finds in Rome Digs,
5614085:House Files Contempt Lawsuit Against Bush Officials,
5622802:House Democrats Defy White House on Spying Program}
Process finished with exit code 0
值得注意的是,第八个聚类的识别非常成功,而前一节的4.5 健壮的链接型聚类(ROCK)则根本没有识别出来。但是它也有瑕疵,5619818:A Facebook Application To Find Blood Donors Fast本应当属于第一个聚类。
4.6.2 DBSCAN的原理
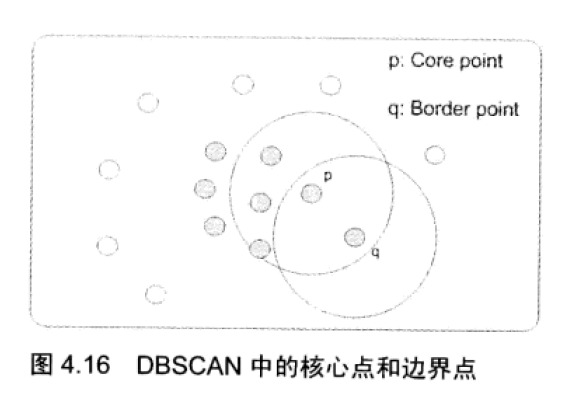
如果点p的eps邻域里至少有minPoints个点,则称其为核心点。如果p在q的eps邻域内,并且,q是核心点,则称数据点q基于密度可直接达到数据点p。这是理解代码所必须的基本概念。
算法将每一个核心点和它邻居里面的核心点归入一个聚类,将其他的点归入噪声,直到所有点都被聚类为止。
package iweb2.ch4.clustering.dbscan;
import iweb2.ch4.model.Cluster;
import iweb2.ch4.model.DataPoint;
import iweb2.ch4.similarity.Distance;
import iweb2.ch4.utils.ObjectToIndexMapping;
import iweb2.ch4.utils.TermFrequencyBuilder;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashSet;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
/**
* Implementation of DBSCAN clustering algorithm.
* <p>
* Algorithm parameters:
* <ol>
* <li>Eps - threshold value to determine point neighbors. Two points are
* neighbors if the distance between them does not exceed this threshold value.
* </li>
* <li>MinPts - minimum number of points in any cluster.</li>
* </ol>
* Choice of parameter values depends on the data.
* </p>
* <p/>
* Point types:
* <ol>
* <li>Core point - point that belongs to the core of the cluster. It has at least
* MinPts neighboring points.</li>
* <li>Border point - is a neighbor to at least one core point but it doesn't
* have enough neighbors to be a core point.</li>
* <li>Noise point - is a point that doesn't belong to any cluster because it is
* not close to any of the core points.</li>
* </ol>
*/
public class DBSCANAlgorithm
{
/*
* Data points for clustering.
*/
private DataPoint[] points;
/*
* Adjacency matrix. Contains distances between points.
*/
private double[][] adjacencyMatrix;
/*
* Threshold value. Determines which points will be considered as
* neighbors. Two points are neighbors if the distance between them does
* not exceed threshold value.
*/
private double eps;
/*
* Identifies a set of Noise points.
*/
private int CLUSTER_ID_NOISE = -1;
/*
* Identifies a set of Unclassified points.
*/
private int CLUSTER_ID_UNCLASSIFIED = 0;
/*
* Sequence that is used to generate next cluster id.
*/
private int nextClusterId = 1;
/*
* Sets of points. Initially all points will be assigned into
* Unclassified points set.
*/
private Map<Integer, Set<DataPoint>> clusters =
new LinkedHashMap<Integer, Set<DataPoint>>();
/*
* Number of points that should exist in the neighborhood for a point
* to be a core point.
*
* Best value for this parameter depends on the data set.
*/
private int minPoints;
private ObjectToIndexMapping<DataPoint> idxMapping =
new ObjectToIndexMapping<DataPoint>();
private boolean verbose = true;
/**
* Initializes algorithm with all data that it needs.
*
* @param points points to cluster 存放数据
* @param adjacencyMatrix adjacency matrix with distances 邻接矩阵
* @param eps distance threshold value 阀值,作为半径
* @param minPoints number of neighbors for point to be considered a core point. 至少邻域内有多少个点才能称得上核心点
*/
public DBSCANAlgorithm(DataPoint[] points, double[][] adjacencyMatrix, double eps, int minPoints)
{
init(points, eps, minPoints);
this.adjacencyMatrix = adjacencyMatrix;
}
/**
* Initializes algorithm with all data that it needs.
*
* @param points all points to cluster
* @param distance metric distance function
* @param eps threshold value used to calculate point neighborhood.
* @param minPoints number of neighbors for point to be considered a core point.
*/
public DBSCANAlgorithm(DataPoint[] points,
Distance distance,
double eps,
int minPoints, boolean useTermFrequencies)
{
init(points, eps, minPoints);
this.adjacencyMatrix =
calculateAdjacencyMatrix(distance, points, useTermFrequencies);
}
private static double[][] calculateAdjacencyMatrix(Distance distance,
DataPoint[] points,
boolean useTermFrequencies)
{
int n = points.length;
double[][] a = new double[n][n];
for (int i = 0; i < n; i++)
{
double[] x = points[i].getNumericAttrValues();
for (int j = i + 1; j < n; j++)
{
double[] y;
if (useTermFrequencies)
{
double[][] tfVectors =
TermFrequencyBuilder.buildTermFrequencyVectors(
points[i].getTextAttrValues(),
points[j].getTextAttrValues());
x = tfVectors[0];
y = tfVectors[1];
}
else
{
y = points[j].getNumericAttrValues();
}
a[i][j] = distance.getDistance(x, y);
a[j][i] = a[i][j];
}
a[i][i] = 0.0;
}
return a;
}
private void init(DataPoint[] points, double neighborThreshold, int minPoints)
{
this.points = points;
this.eps = neighborThreshold;
this.minPoints = minPoints;
for (DataPoint p : points)
{
// Creating a Point <-> Index mappping for all points
idxMapping.getIndex(p);
// Assign all points into "Unclassified" group
assignPointToCluster(p, CLUSTER_ID_UNCLASSIFIED);
}
}
public List<Cluster> cluster()
{
int clusterId = getNextClusterId();
for (DataPoint p : points)
{
if (isUnclassified(p))
{
// 对每一个还未聚类的点,创建一个包含它的聚类
boolean isClusterCreated = createCluster(p, clusterId);
if (isClusterCreated)
{
// Generate id for the next cluster
clusterId = getNextClusterId();
}
}
}
// Convert sets of points into clusters...
List<Cluster> allClusters = new ArrayList<Cluster>();
for (Map.Entry<Integer, Set<DataPoint>> e : clusters.entrySet())
{
String label = String.valueOf(e.getKey());
Set<DataPoint> points = e.getValue();
if (points != null && !points.isEmpty())
{
Cluster cluster = new Cluster(label, e.getValue());
allClusters.add(cluster);
}
}
if (verbose)
{
printResults(allClusters);
}
// Group with Noise elements returned as well
return allClusters;
}
/**
* 为某个点p创建聚类
* @param p
* @param clusterId
* @return 是否是噪点或边界点
*/
private boolean createCluster(DataPoint p, Integer clusterId)
{
boolean isClusterCreated = false;
// 找到eps邻域内的邻居
Set<DataPoint> nPoints = findNeighbors(p, eps);
if (nPoints.size() < minPoints)
{
// Assign point into "Noise" group.
// It will have a chance to become a border point later on.
assignPointToCluster(p, CLUSTER_ID_NOISE);
// return false to indicate that we didn't create any cluster
isClusterCreated = false;
}
else
{
// All points are reachable from the core point...
// 加入聚类
assignPointToCluster(nPoints, clusterId);
// Remove point itself.
// 先从聚类里面删除自身
nPoints.remove(p);
// Process the rest of the neighbors...
// 处理其他邻居
while (nPoints.size() > 0)
{
// pick the first neighbor
DataPoint nPoint = nPoints.iterator().next();
// process neighbor
// 找到eps邻域,判断数据点是否基于密度可直达
Set<DataPoint> nnPoints = findNeighbors(nPoint, eps);
if (nnPoints.size() >= minPoints)
{
// nPoint is another core point.
// nPoint也是一个核心点
for (DataPoint nnPoint : nnPoints)
{
if (isNoise(nnPoint))
{
/* It's a border point. We know that it doesn't have
* enough neighbors to be a core point. Just add it
* to the cluster.
*/
// 如果是边界点,将其分配给相应的聚类
assignPointToCluster(nnPoint, clusterId);
}
else if (isUnclassified(nnPoint))
{
/*
* We don't know if this point has enough neighbors
* to be a core point... add it to the list of points
* to be checked.
*/
// 否则就要判断它是否是核心点,先将它添加到原来的列表中待处理
nPoints.add(nnPoint);
/*
* And assign it to the cluster
*/
assignPointToCluster(nnPoint, clusterId);
}
}
}
else
{
// do nothing. The neighbor is just a border point.
}
// 在继续检查p的邻域中的下一个数据点之前,先将已经检查完的数据点移除
nPoints.remove(nPoint);
}
// return true to indicate that we did create a cluster
isClusterCreated = true;
}
return isClusterCreated;
}
private Set<DataPoint> findNeighbors(DataPoint p, double threshold)
{
Set<DataPoint> neighbors = new HashSet<DataPoint>();
int i = idxMapping.getIndex(p);
for (int j = 0, n = idxMapping.getSize(); j < n; j++)
{
if (adjacencyMatrix[i][j] <= threshold)
{
neighbors.add(idxMapping.getObject(j));
}
}
return neighbors;
}
private boolean isUnclassified(DataPoint p)
{
return isPointInCluster(p, CLUSTER_ID_UNCLASSIFIED);
}
private boolean isNoise(DataPoint p)
{
return isPointInCluster(p, CLUSTER_ID_NOISE);
}
private boolean isPointInCluster(DataPoint p, int clusterId)
{
boolean inCluster = false;
Set<DataPoint> points = clusters.get(clusterId);
if (points != null)
{
inCluster = points.contains(p);
}
return inCluster;
}
private void assignPointToCluster(Set<DataPoint> points, int clusterId)
{
for (DataPoint p : points)
{
assignPointToCluster(p, clusterId);
}
}
private void assignPointToCluster(DataPoint p, int clusterId)
{
// Remove point from the group that it currently belongs to...
if (isNoise(p))
{
removePointFromCluster(p, CLUSTER_ID_NOISE);
}
else if (isUnclassified(p))
{
removePointFromCluster(p, CLUSTER_ID_UNCLASSIFIED);
}
else
{
if (clusterId != CLUSTER_ID_UNCLASSIFIED)
{
throw new RuntimeException(
"Trying to move point that has already been" +
"assigned to some other cluster. Point: " + p + ", clusterId=" + clusterId);
}
else
{
// do nothing. we are registering a brand new point in UNCLASSIFIED set.
}
}
Set<DataPoint> points = clusters.get(clusterId);
if (points == null)
{
points = new HashSet<DataPoint>();
clusters.put(clusterId, points);
}
points.add(p);
}
private boolean removePointFromCluster(DataPoint p, int clusterId)
{
boolean removed = false;
Set<DataPoint> points = clusters.get(clusterId);
if (points != null)
{
removed = points.remove(p);
}
return removed;
}
private int getNextClusterId()
{
return nextClusterId++;
}
public void printDistances()
{
System.out.println("Point Similarity matrix:");
for (int i = 0; i < adjacencyMatrix.length; i++)
{
System.out.println(Arrays.toString(adjacencyMatrix[i]));
}
}
private void printResults(List<Cluster> allClusters)
{
System.out.println("DBSCAN Clustering with NeighborThreshold=" +
this.eps + " minPoints=" + this.minPoints);
System.out.println("Clusters:");
String noiseElements = "no noise elements";
for (Cluster c : allClusters)
{
if (String.valueOf(CLUSTER_ID_NOISE).equals(c.getLabel()))
{
// print noise data at the end
noiseElements = c.getElementsAsString();
}
else
{
System.out.println("____________________________________________________________\n");
System.out.println(c.getLabel() + ": \n" + c.getElementsAsString());
System.out.println("____________________________________________________________\n\n");
}
}
System.out.println("Noise Elements:\n " + noiseElements);
}
public static void main(String[] args)
{
DataPoint[] elements = new DataPoint[5];
elements[0] = new DataPoint("A", new double[]{});
elements[1] = new DataPoint("B", new double[]{});
elements[2] = new DataPoint("C", new double[]{});
elements[3] = new DataPoint("D", new double[]{});
elements[4] = new DataPoint("E", new double[]{});
double[][] a = new double[][]{
{0, 1, 2, 2, 3},
{1, 0, 2, 4, 3},
{2, 2, 0, 1, 5},
{2, 4, 1, 0, 3},
{3, 3, 5, 3, 0}
};
double threshold = 2.0;
int minPoints = 2;
DBSCANAlgorithm dbscan = new DBSCANAlgorithm(elements, a, threshold, minPoints);
dbscan.cluster();
}
}