目录
语义哈希(Semantic hashing)
这节介绍一种检索文档的技术,通过将文档通过语义哈希到不同的内存地址。那么附近的文档都是相似的。
计算文档的二进制编码

上一节用到的网络中,code单元是逻辑斯谛单元,其输出往往位于逻辑斯谛图像的中部,而不是接近0或1的位置,于是不方便转换为二进制。我们可以在fine-tuning的时候,往code单元的输入中加入高斯噪声。这样每个单元的激活值都会往两端极值走,以抵御噪音。然后就可以用阈值去转化为二进制了。Krizhevsky发现完全可以在前向传播的时候将逻辑斯谛单元替换为随机二值单元,根据激活值随机输出0或1。然后在反向传播的时候假装它还是个正常的逻辑斯谛单元去求梯度。这样得到的效果也挺好。
检索
对于二进制的哈希检索来讲,实在是太高效了。30比特对应一个地址,把文档放进去。检索的时候直接去被检索文档的地址就行了,附近就有类似的文档。这种搜索类似于在超市找东西,如果你想买金枪鱼,你可以去卖三文鱼的柜台转转,附近极有可能在卖金枪鱼。超市是二维的,所以不容易把相似的东西放到一起。比如有时候糖果区旁边是服装区,但对30维的空间来讲,放东西就方便多了。

这种检索对大规模文档库而言非常非常高效。
对语义哈希的另一种理解
在文档检索中,有种技术叫倒排文档,也就是记录含有某个词的所有文档。给定搜索串,搜索引擎就可以迅速找出含有串中包含的所有单词的所有文档。
对语义哈希来讲,可以把每一位比特想象为一个搜索词,或者更硬件一点,地址空间中的二进制索引。所以可以在不搜索的情况检索到文档。这种思想还可以泛化到任何事物的检索上去,只要每一比特代表该事物的一个不同的属性就行了。
使用二进制编码检索图片
这一节介绍在图片检索上的应用。256像素的黑白图片可以视作256维的向量。但直接在这么长的向量上做串行搜索实在太慢了,可以利用自动编码器编码一个短一些的code,加快检索速度。
图片检索中的二进制编码
图片检索一般用其标题实现,为什么不用像素呢?
-
像素与词语不同,单个像素含有的信息不多
-
从图片中识别物体曾经是个很难的问题
也许可以从图片中提取一个表示其内容的实值向量,但储存和检索都是大问题。而短小的二进制向量则是更好的选择。
两步法
第一步利用语义哈希得到28比特的二进制向量,然后定位到一个备选图片列表。然后利用256比特的二进制向量去做更好的筛选。
网络结构
这是一个粗糙的结构,没有用什么高级的技巧,结构如下:

输入是32*32的彩色照片,第一层输入拓展到更大的8192个单元,然后逐层编码到256个比特。
重建
从code到图片的重建效果如下:

检索
用这256比特检索与用像素强度在欧几里得空间检索的结果如下:

图片上方标注的是差异的值。可见自动编码器的效果要好很多,它找到的图片几乎都是人脸。
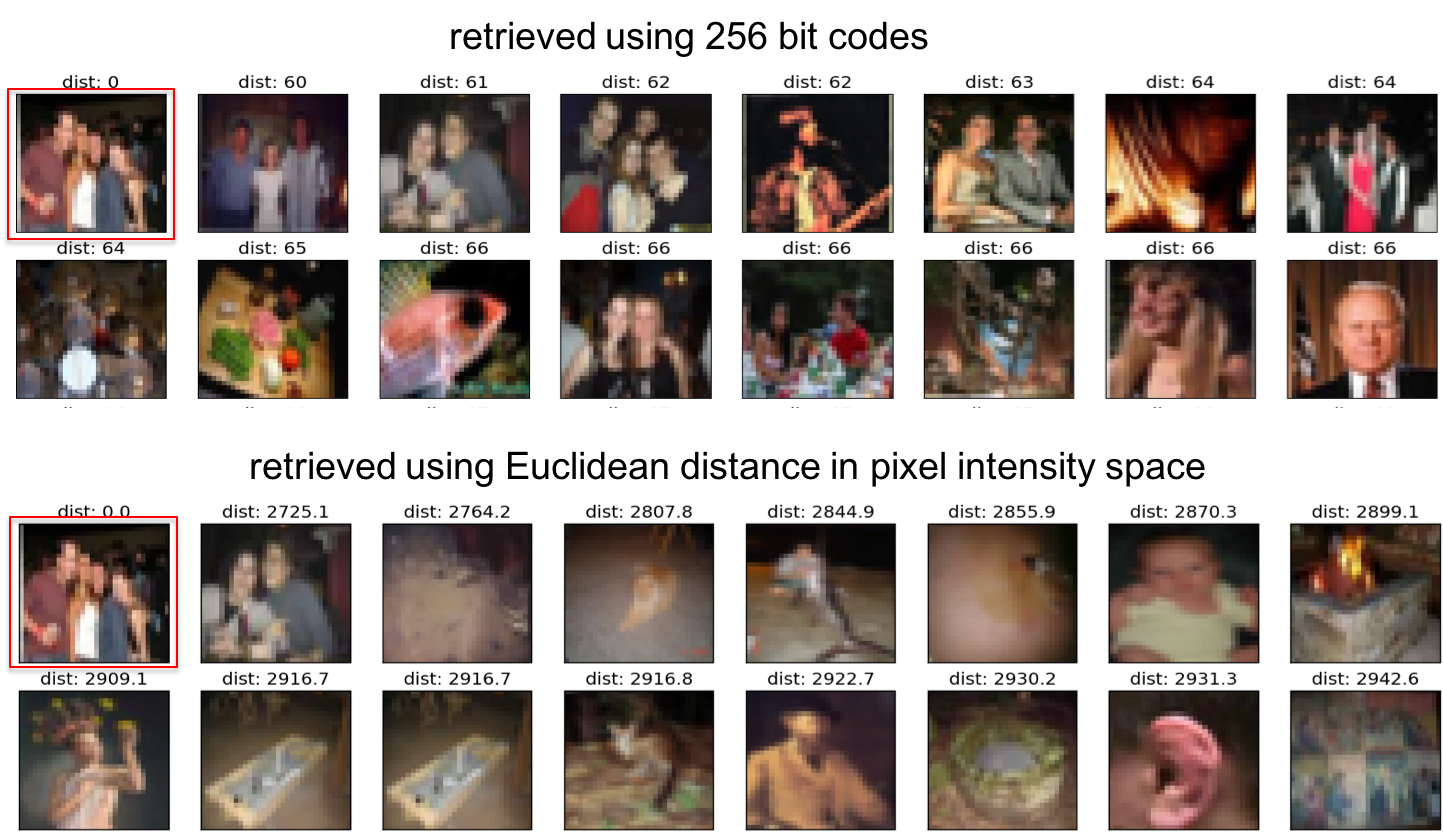
在这个例子中,自动编码器找到的例子大多数是人群的合影,少数是误命中。但它们都有相同的特点,那就是中间有一个明亮的区域。
而欧几里得空间上根据距离检索的效果就要差太多了,该方法倾向于找出那些“平滑”的图片,因为它是最小化距离(各个维度上的误差的平方和)。
让搜索引擎更关注图片内容而不是像素
上述方法还可以改进。
先训练一个大型网络识别图片中的物体(第五课有讲),然后利用最后一个隐藏层的激活值作为图像的表示。虽然可以进一步编码成更短的二进制,但直接在这个激活值向量上做欧式空间的距离检索,也能拿到非常好的效果。

最左边是query,其他是结果。虽然结果与query并没有多少重叠的像素,但就是能够检索出来。在第16课中会介绍将图片与标题合并起来得到更好效果的例子。
Shallow autoencoders for pre-training
这一节介绍pre-training 的替代方法,而不再局限于RBM的pre-training。
将RBM作为自动编码器
称只有一个隐藏层的自动编码器为Shallow autoencoders。
使用最大似然训练的RBM不像自动编码器(偏置的影响),但使用CD1训练的RBM则很像自动编码器,并且由于二值激活值的限制,它被强烈地正则化了。
也许可以用层叠的RBM去替代层叠的Shallow autoencoders?但这样的预训练并不如L2正则的Shallow autoencoders好。
Denoising autoencoders
这种Denoising autoencoders 可以做到一样的效果。它将输入向量上许多维度设为0,但不同的训练实例操纵不同的维度(有点像Dropout,但后者是加在激活值上的)。如果要利用这些残缺的输入重建输入,则要求模型捕捉输入之间的关系。这克服了Shallow autoencoders的懒惰现象:如果隐藏单元很多,则编码器会简单地将像素拷贝到隐藏单元上,而不是在更高的层次上表示它们。
通过层叠Denoising autoencoders比RBM的pre-training效果相当或更好。评估也更方便,因为RBM没有目标函数,只能以平方误差替代,但后者并不是优化目标。
Contractive autoencoders
另一种正则化自动编码器的方法是让隐藏单元的激活值对输入不敏感(但也不能完全忽略输入)。这可以通过惩罚每个隐藏单元激活值对输入的梯度来实现。
这种编码器pre-training的效果很好,它倾向于对每个训练实例,只激活一小部分隐藏单元。但每个训练实例激活的子集差异非常大,也就是说激活单元是稀疏的,这与RBM是类似的。
总结pre-training
在标注数据很少未标注数据很多的情况下,可以利用非常多的手段去做 layer-by-layer pre-training。pre-training可以获取参数的一个较好的初始值,发现许多好的特征表示,帮助接下来的discriminative learning。
但对于大规模标注数据集来讲,即便是较深的网络,pre-training也不是必须。因为现在有很多其他的手段。但是网络再大一点的时候,又需要pre-training了。
老爷子说跟Google的人经常发生如下争论:
谷歌:我们财大气粗,有大量的标注数据,所以不需要正则化。
Hinton:那是因为你们网络不够深,你们应该加入更多的层,在更强大的机器上训练。那时候你们就需要正则化了!
对于大脑来讲,其神经元(参数)的数量是远远大于数据量的,所以regularization methods对它而言肯定非常重要。
References
![]() A synopsis of Hilbert space theory.pdf
A synopsis of Hilbert space theory.pdf
![]() 知识共享署名-非商业性使用-相同方式共享:码农场 » Hinton神经网络公开课15 Modeling hierarchical structure with neural nets
知识共享署名-非商业性使用-相同方式共享:码农场 » Hinton神经网络公开课15 Modeling hierarchical structure with neural nets